

We all make mistakes, and we can all learn from other people’s mistakes. In this post, we’ll take a look at numerous online resources for avoiding poor database design that can lead to many problems and cost both time and money. And in an upcoming article, we’ll tell you where to find tips and best practices.
Database Design Errors and Mistakes to Avoid
There are numerous online resources to help database designers avoid common errors and mistakes. Obviously, this article is not an exhaustive list of every article out there. Instead, we’ve reviewed and commented on a variety of different sources so that you can find the one that best suits you.
Our recommendation
If there is only one article among these resources that you are going to read, it should be ‘How to get Database Design Horribly Wrong’ from Robert Sheldon
Let’s start with the DATAVERSITY blog that provides a broad set of quite good resources:
Primary Key and Foreign Key Errors to Avoid
by Michael Blaha | DATAVERSITY blog | September 2, 2015
More Database Design Errors – Confusion with Many-to-Many Relationships
by Michael Blaha | DATAVERSITY blog | September 30, 2015
Miscellaneous Database Design Errors
by Michael Blaha | DATAVERSITY blog | October 26, 2015
Michael Blaha has contributed a nice set of three articles. Each article addresses different pitfalls of database modeling and physical design; topics include keys, relationships, and general errors. In addition, there are discussions with Michael regarding some of the points. If you’re looking for pitfalls around keys and relationships, this would be a good place to start.
Mr. Blaha states that “about 20% of databases violate primary key rules”. Wow! That means that about 20% of database developers did not properly create primary keys. If this statistic is true, then it really shows the importance of data modelling tools that strongly “encourage” or even require modelers to define primary keys.
Mr. Blaha also shares the heuristic that “about 50% of databases” have foreign key problems (according to his experience with legacy databases that he has studied). He reminds us to avoid informal linkage between tables by embedding the value from one table into another rather than using a foreign key.
I have seen this problem many times. I admit that informal linkage can be required by the functionality to be implemented, but more often it occurs due to simple laziness. For example, we may want to show the user id of someone who modified something, so we store the user id directly in the table. But what if that user changes his/her user id? Then this informal link is broken. This is often due to poor design and modelling.
Designing Your Database: Top 5 Mistakes to Avoid
by Henrique Netzka | DATAVERSITY blog | November 2, 2015
I was a little disappointed by this article, as it had a couple of quite specific items (storing protocol in a CLOB) and a few very general ones (think about localization). Overall, the article is fine, but are these really the top 5 mistakes to be avoided? In my opinion, there are several other common mistakes that should make the list.
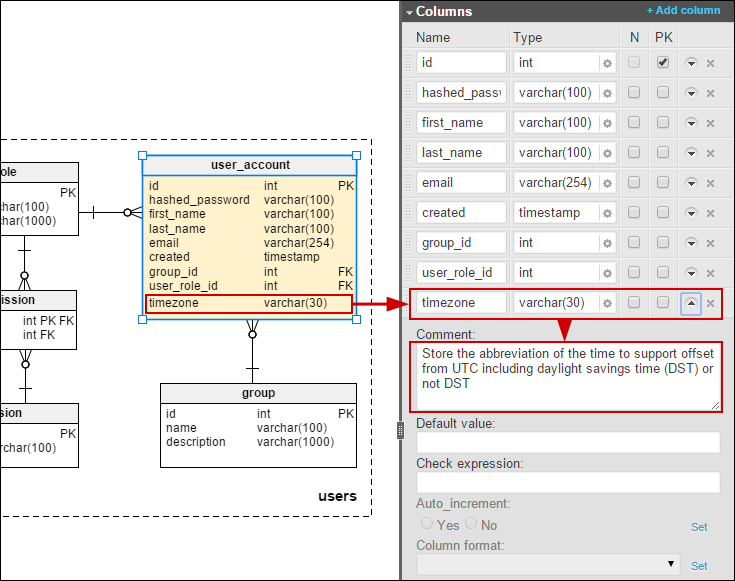
However, on a positive note, this is one of the few articles that mentions globalization and localization in any meaningful way. I work in a very multi-lingual environment and have seen several horrible implementations of localization, so I was happy to find this issue mentioned. Language columns and time zone columns may seem obvious, but they appear very rarely in database models.
That being said, I thought it would be interesting to create a model including translations that can be altered by end users (as opposed to using resource bundles). Some time ago, I wrote about a model for an online survey database. Here I have modelled a simplified translation of questions and response choices:
Assuming that we must allow end users to maintain the translations, the preferred method would be to add translation tables for questions and responses:
I have also added a time zone to the user_account table so that we can store dates/times in the users’ local time:
7 common database design errors
by Grzegorz Kaczor | Vertabelo blog | July 17, 2015
I will make a little self-promotion here. We strive to regularly post interesting and engaging articles here.
This particular article points out several important areas of concern, like naming, indexing, volume considerations, and audit trails. The article even goes into issues related to specific DBM systems, like Oracle limitations on table names. I really like nice clear examples, even if they are illustrating how designers make mistakes and errors.
Obviously it’s not possible to list every design error, and the ones listed might not be your most common errors. When we write about common mistakes, it’s the ones we have made or have found in others’ work that we’re drawing on. A complete list of errors, ranked in terms of frequency, would be impossible for a single person to compile. Nevertheless, I think that this article provides several useful insights about potential pitfalls. It is a nice solid resource overall.
While Mr. Kaczor makes several interesting points in his article, I found his comments about “not considering possible volume or traffic” quite interesting. In particular, the recommendation to separate frequently-used data from historical data is particularly pertinent. This is a solution that we use frequently in our messaging applications; we must have a searchable history of all messages, but the messages most likely to be accessed are those that have been posted within the past few days. So splitting “active” or recent data that is frequently accessed (a much smaller volume of data) from long-term historic data (the large mass of data) is generally a very good technique.
Common Database Design Mistakes
by Troy Blake | Senior DBA blog | July 11, 2015

Troy Blake’s article is another good resource, although I might have renamed this article “Common SQL Server Design Mistakes”.
For example, we have the comment: “stored procedures are your best friend when it comes to using SQL Server effectively”. That’s fine, but is this a common general mistake, or is it more specific to SQL Server? I would have to opt for this being a bit SQL Server-specific, as there are disadvantages to using stored procedures, like ending up with vendor-specific stored procedures and thus vendor lock-in. So I am not a fan of including “Not Using Stored Procedures” on this list.
However, on the positive side, I think that the author did identify some very common mistakes, like poor planning, shoddy system design, limited documentation, weak naming standards, and a lack of testing.
So I would classify this as a very useful reference for SQL Server practitioners and a useful reference for others.
Seven Data Modeling Mistakes
by Kurt Cagle | LinkedIn | June 12, 2015
I really enjoyed reading Mr. Cagle’s list of database modelling mistakes. These are from a database architect’s view of things; he clearly identifies higher-level modeling mistakes that should be avoided. With this bigger picture view, you can abort a potential modelling mess.
Some of the types mentioned in the article can be found elsewhere, but a few of these are unique: getting abstract too early or mixing conceptual, logical, and physical models. Those are not often mentioned by other authors, probably because they are focusing on the data modelling process rather than the bigger system view.
In particular, the example of “Getting Too Abstract Too Early” describes an interesting thought process of creating some sample “stories” and testing which relationships are important in this domain. This focuses the thinking on the relationships between the objects being modelled. It results in questions like what are the important relationships in this domain?
Based on this understanding, we create the model around relationships rather than starting at individual domain items and building the relationships on top of them. While many of us might use this approach, among these resources no other author commented on it. I found this description and the examples quite interesting.
How to get Database Design Horribly Wrong
by Robert Sheldon | Simple Talk | March 6, 2015
If there is only one article among these resources that you are going to read, it should be this one from Robert Sheldon
What I really like about this article is that for each of the mistakes mentioned there are tips on how to do it right. Most of these focus on avoiding the failure rather than correcting it, but I still think that they are very useful. There is very little theory here; mostly straight answers about avoiding mistakes while data modeling. There are a few specific SQL Server points, but mostly SQL Server is used to provide examples of error avoidance or ways out of failure.
The scope of the article is also quite broad: it covers neglecting to plan, not bothering with documentation, using lousy naming conventions, having issues in normalization (too much or too little), failing on keys and constraints, not properly indexing, and performing inadequate testing.
In particular, I liked the practical advice regarding data integrity – when to use check constraints and when to define foreign keys. In addition, Mr. Sheldon also describes the situation when teams defer to the application to enforce integrity. He is straight on point when he states that a database can be accessed in multiple ways and by numerous applications. His concludes that “data should be protected where it resides: within the database”. This is so true that it can be repeated to development teams and managers to explain the importance of implementing integrity checks in the data model.
This is my kind of article, and you can tell that others agree based on the numerous comments endorsing it. So, top marks here; it is a very valuable resource.
Ten Common Database Design Mistakes
by Louis Davidson | Simple Talk | February 26, 2007
I found this article quite good, as it covered a lot of common design mistakes. There were meaningful analogies, examples, models, and even some classic quotes from William Shakespeare and J.R.R. Tolkien.
A couple of the mistakes were explained in greater detail than others, with long examples and SQL excerpts that I found a bit cumbersome. But that is a matter of taste.
Again, we have a few topics specific to SQL Server. For example, the point of not using Stored Procedures to access data is good for SQL, but SPs are not always a good idea when the goal is support on multiple DBMSes. In addition, we are warned against trying to code generic T-SQL objects. As I rarely work with SQL Server or Sybase, I did not find this tip relevant.
The list is quite similar to Robert Sheldon’s, but if you are primarily working on SQL Server, then you will find a few additional nuggets of information.
Five Simple Database Design Errors You Should Avoid
by Anith Sen Larson | Simple Talk | October 16, 2009
This article gives some meaningful examples for each of the simple design errors it covers. On the other hand, it is rather focused on similar types of errors: common lookup tables, entity-attribute-value tables, and attribute splitting.
The observations are fine, and the article even has references, which tend to be rare. Still, I would like to see more general database design errors. These errors seemed rather specific, but, as I have already written, the mistakes we write about are generally those that we have personal experience with.
One item that I did like was a specific rule of thumb for deciding when to use a check constraint versus a separate table with a foreign key constraint. Several authors provide similar recommendations, but Mr. Larson breaks them down into “must”, “consider” and “strong case” – with the admission that “design is a mix of art and science and therefore it involves tradeoffs”. I find this very true.
Top Ten Most Common Physical Database Design Mistakes
by Craig Mullins | Data and Technology Today | August 5, 2013
As its name implies, “Top Ten Most Common Physical Database Design Mistakes” is slightly more oriented to physical design rather than logical and conceptual design. None of the mistakes author Craig Mullins mentions really stands out or is unique, so I would recommend this information to folks working on the physical DBA side.
In addition, the descriptions are a bit short, so it is occasionally hard to see why a particular mistake is going to cause problems. There is nothing inherently wrong with short descriptions, but they don’t give you very much to think about. And no examples are presented.
There is one interesting point raised relating to the failure to share data. This point is occasionally mentioned in other articles, but not as a design mistake. However, I see this issue quite frequently with databases being “re-created” based on very similar requirements, but by a new team or for a new product
.It often happens that the product team realizes later that they would have liked to use data that was already present in the “father” of their current database. In actual fact, though, they should have enhanced the parent rather than creating a new offspring. Applications are meant to share data; good design can allow a database to be reused more often.
Do you make these 5 database design mistakes?
by Thomas Larock | Thomas Larock’s blog | January 2, 2012
You might find a few interesting points as you answer Thomas Larock’s question: Do You Make These 5 Database Design Mistakes?
This article is somewhat heavily weighted to keys (foreign keys, surrogate keys, and generated keys). Yet, it does have one important point: one should not assume that DBMS features are the same across all systems. I think this is a very good point. It is also one that is not found in most other articles, perhaps because many authors focus on and work predominantly with a single DBMS.
Designing a Database: 7 Things You Don’t Want To Do
by Thomas Larock | Thomas Larock’s blog | January 16, 2013

Mr. Larock recycled a couple of his “5 Database Design Mistakes” when writing “7 Things You Don’t Want To Do”, but there are other good points here.
Interestingly, some of the points that Mr. Larock makes are not found in many other sources. You do get a couple of rather unique observations, like “having no performance expectations”. This is a serious mistake and one that, based on my experience, happens quite often. Even when developing the application code, it is often after the data model, the database, and the application itself have been created that people start thinking about the non-functional requirements (when non-functional tests must be created) and start defining performance expectations.
Conversely, there are a few points that I would not include in my own Top Ten list, such as “going big, just in case”. I see the point, but it’s not that high on my list when creating a data model. There is no specificity to a particular DBM system, so that is a bonus.
To conclude, many of these points might be encapsulated under the point: “not understanding the requirements”, which really is in my Top 10 mistake list.
How To Avoid 8 Common Database Development Mistakes
by Base36 | December 6, 2012

I was quite interested in reading this article. However, I was a bit disappointed. There is not much discussion about avoidance, and point of the article really seems to be “these are common database mistakes” and “why they are mistakes”; descriptions of how to avoid the mistake are less prominent.
In addition, some of the article’s Top 8 errors are actually disputed. Misuse of the primary key is an example. Base36 tells us that they must be generated by the system and not based on application data in the row. While I agree with this up to a point, I am not convinced that all PKs should always be generated; that is a bit too categorical.
On the other hand, the mistake of “Hard Deletes” is interesting and not often mentioned elsewhere. Soft deletes do cause other issues, but it is true that simply marking a row as inactive does have its advantages when you are trying to figure out where that data went that was in the system yesterday. Searching through transaction logs is not my idea of an enjoyable way to spend a day.
Seven Deadly Sins of Database Design
by Jason Tiret | Enterprise Systems Journal | February 16, 2010
I was quite hopeful when I started reading Jason Tiret’s article, “Seven Deadly Sins of Database Design”. So I was happy to find that it didn’t just recycle mistakes that are found in numerous other articles. On the contrary, it offered a “sin” that I had not found in other lists: trying to perform all database design “up front” and not updating the model after the database is in production, when changes are made to the database. (Or, as Jason puts it, “Not treating the data model like a living, breathing organism”).
I have seen this mistake many times. Most people only realize their error when they must make updates to a model which no longer matches the actual database. Of course, the result is a useless model. As the article states, “the changes need to find their way back to the model.”
On the other hand, the majority of Jason’s list items are quite well known. The descriptions are good, but there are not very many examples. More examples and details would be useful.
The Most Common Database Design Mistakes
by Brian Prince | eWeek.com | March 19, 2008

“The Most Common Database Design Mistakes” article is actually a series of slides from a presentation. There are a few interesting thoughts, but some of the unique items are perhaps a bit esoteric. I have in mind points like “Get to know RAID” and stakeholder involvement.
In general, I would not put this on your reading list unless you are focused on general issues (planning, naming, normalization, indexes) and physical details.
10 common design mistakes
by davidm | SQL Server Blogs – SQLTeam.com | September 12, 2005
Some of the points in “Ten common design mistakes” are interesting and relatively novel. However, some of these mistakes are quite controversial, such as “using NULLs” and de-normalizing.
I agree that creating all columns as nullable is a mistake, but defining a column as nullable may be required for a particular business function. Can it therefore be considered as a generic mistake? I think not.
Another point I take issue with is de-normalization. This is not always a design error. For example, de-normalization may be required for performance reasons.
This article is also largely lacking in details and examples. The conversations between DBA and programmer or manager are amusing, but I would have preferred more concrete examples and detailed justifications for these common mistakes.
OTLT and EAV: the two big design mistakes all beginners make
by Tony Andrews | Tony Andrews on Oracle and Databases | October 21, 2004
Mr. Andrews’ article reminds us of the “One True Lookup Table” (OTLT) and Entity-Attribute-Value (EAV) mistakes that are mentioned in other articles. One nice point about this presentation is that it focuses on these two mistakes, so descriptions and examples are precise. In addition, a possible explanation of why some designers implement OTLT and EAV is given.
To remind you, the OTLT table typically looks something like this, with entries from multiple domains thrown into the same table:
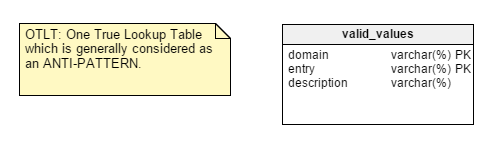
As usual, there is a discussion around whether OTLT is a workable solution and a good design pattern. I must say that I side with the anti-OTLT group; these tables introduce numerous issues. We might use the analogy of using a single enumerator to represent all possible values of all possible constants. I have never seen that, so far.
Common Database Mistakes
by John Paul Ashenfelter | Dr. Dobb’s | January 01, 2002
Mr. Ashenfelter’s article lists a whopping 15 common database mistakes. There are even a few mistakes that are not frequently mentioned in other articles. Unfortunately, the descriptions are relatively short and there are no examples. This article’s merit is that the list covers a lot of ground and can be used as a “checklist” of mistakes to avoid. While I might not classify these as the most important database mistakes, they are certainly among the most common.
On a positive note, this is one of the few articles that mentions the need to handle internationalization of formats for data like date, currency and address. An example would be nice here. It could be as simple as “be sure that State is a nullable column; in many countries, there is no state associated with an address”.
Earlier in this article, I mentioned other concerns and some approaches to prepare for globalization of your database, like time zones and translations (localization). The fact that no other article mentions the concern of currency and date formats is troubling. Are our databases prepared for the global usage of our applications?
Honorable Mentions
Obviously, there are other articles that describe common database design mistakes and errors, but we wanted to give you a broad review of different resources. You can find additional information in articles such as:
10 Common Database Design Mistakes | MIS Class Blog | January 29, 2012
10 Common Mistakes in Database Design | IDG.se | June 24, 2010
Online Resources: Where to start? Where to go?
As previously mentioned, this list is definitely not meant to be an exhaustive examination of every online article describing database design mistakes and errors. Rather, we have identified several sources that are particularly useful or have a specific focus that you might find useful.
Please feel free to recommend additional articles.
