

Many freelancers find projects on online job platforms like Upwork and Freelancer. What kind of database model powers these sites? Let’s take a look ...
If you’re not a freelancer, you probably know somebody who is. Working anytime and from almost anywhere is very attractive, and thanks to online freelancing sites, it’s a real possibility. And we’re not talking about just IT-related jobs like programming and project management. Freelance jobs include teaching, writing, composing music, illustrating, and design.
So it’s no surprise that freelancing is becoming more common, and it will continue to grow and even change the job market. To run everything smoothly, we’ll need a platform that connects clients with freelancers. Two such popular platforms are Upwork and Freelancer.com. In this article, we’ll explain the data model that is behind these platforms.
How Do Freelancing Job Platforms Work?
If you’re not familiar with using a freelance platform, it will help if you understand the following points before we continue.
Where Does the Word “Freelance” Come From?
As you might guess, “freelance” comes from the words “free” and “lance”. It dates from the 18th century and described a mercenary willing to join a cause for a fee. The term was coined in the ages when weapons like lances were obviously much more popular than they are today. Luckily, lances have now been replaced with keyboards! ☺
The connotation is that someone would work (or fight) for a period of time, rather than on a permanent basis.
How Are Projects Posted on These Sites? How Do Freelancers Get Hired?
I’ll keep it simple. Both clients and freelancers must create an account before they can work or hire. The client posts a job or project together with its details, expected duration, and the amount they’re willing to pay (either a fixed amount or a per-hour fee). Freelancers can search or browse through job listings. If they are interested in a job, they bid for it by explaining their qualifications and their fees. The client then chooses one or more freelancers and starts the project.
How Are Freelancing Platforms Funded?
In most cases, either the freelancer or the client pay a fee for each payment. This is usually based on the project price (anywhere from 5 to 20 percent of the project fee). Sometimes, paid user accounts are also used to generate revenue.
The Online Freelance Job Platform Model
I split this model into four subject areas:
- Clients
- Freelancers
- Job Posts
- Proposals and Contracts
and three standalone tables:
- User_account
- Skill
- Payment_type
Let’s start with the User_account table.
The User Account Table
We’ll have at least two types of users: clients and freelancers. These are not mutually exclusive roles; any user can be both at the same time. Maybe one user is primarily a freelancer, but he or she hires another freelancer for some activities. So this user fills both roles – hire manager and freelancer.
We could have created a single table and then used roles and a key-value structure for specific details, but I prefer to go with three separate tables. The first table, user_account, will store each user’s personal data and login information.
The remaining two tables, which are in the Client area, will have details about hire managers and freelancers, respectively. If one user fills both roles, a record will be inserted into both tables and the user will be able to switch between roles on the site’s interface.

So, let’s look at the user_account table. This table stores only the attributes that are important during the user registration and login processes, such as the user’s first and last name. The user_name and email attributes are the alternate (unique) keys of this table.

This is also a good time to mention the payment_type dictionary, as it will be used in several areas. The only attribute in this standalone table is the type_name field, which is the alternate key of the table. We can expect at least two values here: “per hour” and “fixed price”.
Now, let’s move on to the Client area of our data model.
The Client Area
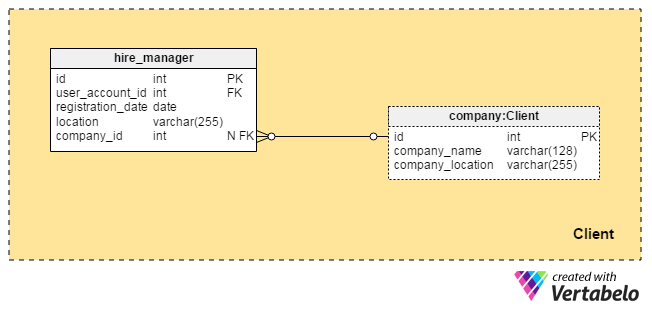
This area consists of only two tables. The first is the hire_manager table. The hire manager posts jobs and hires freelancers. Hire managers can be related to a company, and a company can have several hire managers using the platform. These two tables, hire_manager and company, form the Client area. Note that the “company” table is named company:Client because we will use it twice (once as a shortcut) in our model. Let’s take a quick look at the attributes:
user_account_id– This is a reference to a specific hire manager’s user account. Only one hire manager can be related to one user account, so this is a unique attribute.registration_date– This field stores the date when this user registered with the platform as a hire manager. Users can have two registration dates, one as a freelancer and the other as a hire manager. This way, we’ll be able to keep track of when they started to use each role. The date with the lower value is the actual registration date for the user account.location– This is a description of the hire manager’s location (usually city and country.)company_id– This is a reference to the related company, if any.
The company table is quite simple and it only contains attributes to store the organization’s name and location, as well as an ID number that is referenced by the hire_manager table.
There are many other details we could store about hire managers that would require dictionaries (e.g. a location dictionary) and additional text fields. Also, some interesting attributes could be computed from our database and stored as redundant values. A few examples are: the number of jobs posted by client, the client’s number of hires, total money spent on freelance projects, and the client’s overall feedback score (based on feedback received from freelancers).
The Freelancer Area
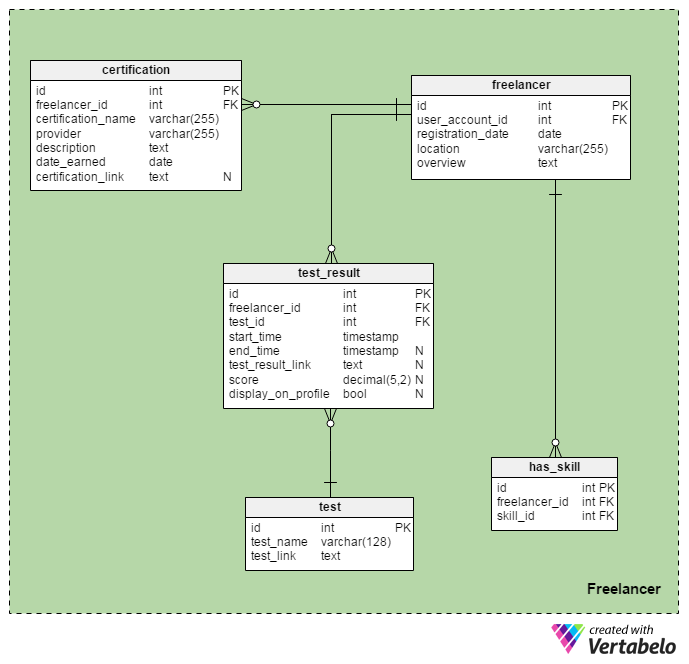
The Freelancer area is composed of five tables that describe freelancers and their abilities.
The central table in this area is the freelancer table. It follows the same pattern as the hire_manager table. The only two differences are:
- The
overviewattribute is where we’ll store the freelancer’s description of their services, experience, and skills. - A freelancer doesn’t belong to a company. (Sometimes the freelancer may be part of an agency or a larger group, but he or she will still use this platform as an individual rather than a company.)
An important part of a freelancer’s profile is their certifications. There are numerous certifications today and we simply can’t create a single dictionary to store them all. Therefore, the certification table contains only descriptive attributes (aside from the freelancer’s ID):
certification_nameand provider – These store the name of the certification and the institution that issued it.description– This is a description of the certification, written by the freelancer.date_earned– This is the date when the certificate was issued.certification_issued– This is a link to the freelancer’s certificate, if available.
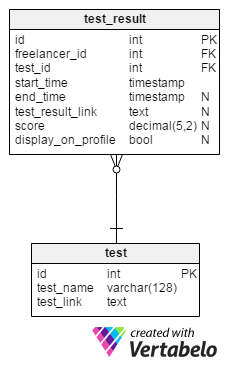
Tests, like certifications, are a way for freelancers to present their skills to the public. Tests are especially important for new freelancers, particularly those that don’t have a portfolio, because they help them quantify their skills and set themselves apart from other freelancers.
Most freelance platforms offer tests to measure various skills. We’ll store a list of all such tests in the test catalog. The test_name attribute is the alternate (unique) key of the table, while the test_link attribute stores the actual location where we’ll access the test and all its questions.
We’ll use the test_result table to store the results freelancers achieve. To do so, we’ll need the following attributes:
freelancer_id– This is the ID of the freelancer who took the test.test_id– This is the ID, from thetestcatalog table, of the test taken by the freelancer.start_timeandend_time– These attributes are timestamps denoting when the test was taken.test_result_link– Here we’ll store a link to that test instance and the actual answers given by the freelancer.score– This holds the test score, usually shown in points or as a percentage.display_on_profile– This allows the freelancer to show their test results on their profile (or not). It is a Boolean value set by the user.
Note that the last four attributes of this table can contain NULL values. This is because we’ll update them with values when the freelancer completes the test.
Finally, freelancers can simply self-report their job-related skills on their profiles. We’ll relate freelancers and the skills they possess using the has_skill table. A freelancer can choose from a list of skills. The freelancer_id – skill_id pair is the alternate key of this table.
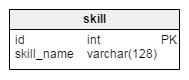
We’ve already mentioned the skill dictionary. (Although we’ll discuss it here, this table is actually one of the standalone tables.) In this case, “skills” are used as tags to describe the freelancer’s knowledge. In the Job Posts context, “skills” describe project requirements. The only attribute in the table, aside from the primary key, is skill_name. Since this attribute defines one skill, it is also a unique key for this table.
The Job Posts Area
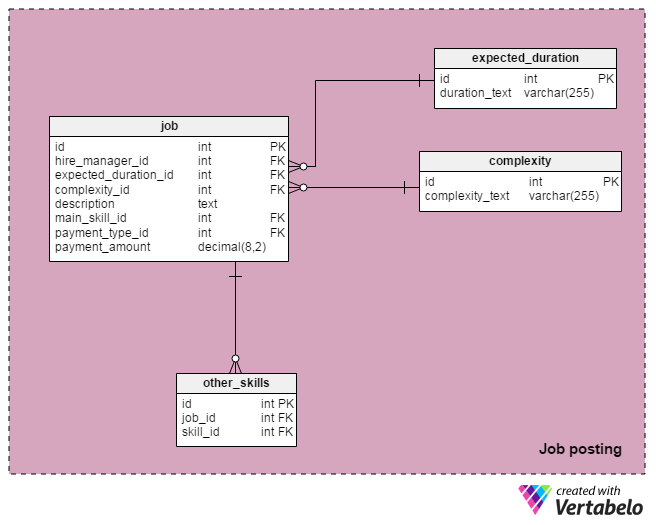
The Job Posts area contains tables that describe the jobs posted.
The expected_duration table is a dictionary with a list of all supported job durations. It contains values like “1 day”, “2-5 days”, “5-10 days”, “less than 1 month”, “1-3 months”, “3-6 months” and “6 or more months”.
We’ll use the complexity dictionary to help hire managers approximately describe their job’s complexity. Expected values include “easy”, “intermediate” and “hard”.
Both of these dictionaries have only one attribute which also serves as the unique key of the table.
The most important table in this area is the job table. Here we’ll define nearly every detail related to a job post. Here are the attributes:
hire_manager_id– This is the ID of the hire manager that posted this job.expected_duration_idandcomplexity_id– These self-explanatory values are set by the hire manager when he or she posts the job.description– This is a detailed description of the project.main_skill_id– This attribute is a reference to theskilldictionary, indicating the most important skill needed to successfully complete this job.payment_type_idandpayment_amount– Two more attributes that define how much the hire manager is willing to pay for this job.
In the other_skill table, we’ll list any additional skills required for a certain job. As this table is composed of only foreign key attributes, the foreign key attribute pair (job_id – skill_id) is a UNIQUE value.
The Proposals and Contracts Area
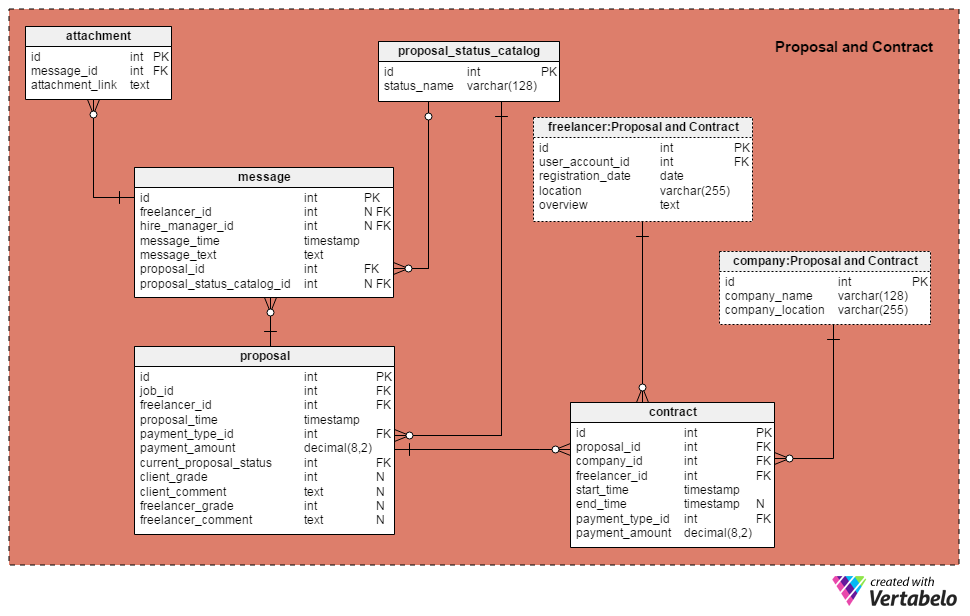
The last area in our model is the Proposals and Contracts area. This is where we’ll store all proposals, contracts, and communications between clients and freelancers.
Notice that the freelancer and company tables are shown in this area. Actually, these are only shortcuts that I’ve placed here to simplify the model.
Let’s begin with the proposal_status_catalog dictionary; two tables in this area use it. In this dictionary we’ll store values like: “proposal sent”, “negotiation phase”, “proposal withdrawn”, “proposal rejected”, “proposal accepted”, “job started”, ”job finished (successfully)”, “job finished (unsuccessfully)”. As you can see from these values, the intention is to track proposal status and what happens after the job is underway.
The central table in this section is the proposal table. Here we’ll store every proposal ever made on our platform. The attributes in the table are:
job_id– This is a reference to the related ID field in thejobtable.freelancer_id– This is a reference to the ID of the freelancer who submitted the proposal.proposal_time– Here we’ll store a timestamp for when the proposal was submitted.payment_type_idandpayment_amount– These make up the amount the freelancer expects to get paid for the job.current_proposal_status– This is a reference to theproposal_status_catalogtable.client_gradeandclient_comment– These make up the client’s feedback for the freelancer after the job is completed. These fields are nullable, since leaving feedback is optional.freelancer_gradeandfreelancer_comment– These make up the freelancer’s feedback for the client after the job is completed. These fields are nullable, since leaving feedback is optional.
If a freelancer and hire manager decide to work together, they’ll “sign” a contract. We’ll store all such contracts in the contract table. For each contract, we’ll save the related proposal ID, company ID, freelancer ID, start time and agreed payment type and amount. We’ll update the end_time attribute at the moment the job is finished. The company_id and freelancer_id attributes are redundant data. We could get these values by joining the freelancer and company table via other tables in the model. Still, it’s nice to have these attributes here because it will simplify query writing later.
We’ll store all communications between the hire manager and the freelancer in the message table. One must send a message to the other, so both freelancer_id and hire_manager_id are marked IS NOT NULL.
The message_time attribute stores the actual timestamp when the message was sent; the message_text stores its content.
We’ll also need to relate each message with the appropriate record in the proposal table. If the message changed the proposal status, we’ll store a new status in the proposal_status_catalog_id attribute (and update proposal.current_proposal_status at the same time). This is one way we can track everything that happens with a proposal (and a contract, if one is signed).
The last table in this area and in our model is the attachment table. My idea was that a person who sends a message can attach as many files as they want to it. Therefore, the attachment table contains a reference to the message table as well the actual attachment_link.
What Would You Add to This Model?
In this article we discussed a model for a freelance job platform. I tried to cover the most common functionalities. Still, there are more that we could add. I’ll name some of them:
- The capability for hire managers to contact freelancers directly through the freelancers’ profiles
- Paid memberships with more features
- A way to change proposal conditions
- Somewhere to store old values
What would you add? What would you change? Please let us know!
