

Mail delivery, in spite our dependence on email, is still alive and well. What kind of data model supports your local mail delivery?
A few decades ago, mail (not email) was one of the most important ways to communicate. We received all kinds of mail, from bills and advertisements to letters and invitations. Maybe you got mail from long-lost relatives in Australia or even a Nigerian prince with an unbelievable fortune just waiting for you 😊. Email is faster and cheaper, but I still have some nostalgia for the excitement of my daily mail delivery.
Posts used to be largely state-owned companies that had a lot of weight and influence. The local postman was like an institution, especially in smaller communities. Now postal services have many competitors. Still, mail must be delivered and it has to go to the right address. Today we’ll peek into a data model to help us with that.
What Should Be Included in Our Data Model?
Although this topic is pretty much self-explanatory – we all know how it works – I still want to highlight some important parts of the mail delivery process.
-
1. What are the most important parts of mail delivery?
Before we can even talk about the delivery system, there are many prerequisites we need to discuss first. Any kind of letter or package delivery system has at least three very important parts. (Although postal vans and other carriers deliver letters and packages, for convenience’s sake we’ll refer to the thing being delivered as “mail” no matter what it is.)
These parts are:
- A place (or places) where mail is collected. This usually means we’ll also have a defined procedure for mail collection.
- A place where collected mail is sorted and processed.
- A process for delivering mail to the recipients. We’ll also need some rules to follow for special situations (e.g. recipient needs to sign for a delivery; the carrier is unable to deliver something, etc).
We also have to keep track of our personnel. Although there are many employees who work behind the scenes (i.e. sorting and processing mail, doing sales and customer service), we’ll primarily be concerned with tracking which mail carrier is assigned to which batch of mail.
Of course, these are just basic requirements. We’ll discuss a few more detailed requirements as we deal with the relevant subject areas.
-
2. How will we use this data model?
The idea is that we’ll have a web or mobile application (or probably both) that uses this data model. When each physical action happens, the employee will update the status for that item in the database. So when a postal employee in the local office checks in some mail, cancels the stamps, and puts the mail in the “outgoing mail” bin, they would change the status of that mail item. Depending on the mail, the place, and the system, this mail would either be passed to another office for more processing or assigned out to a carrier.
When the mail carrier brings collected mail to the post office, we should also have that info. That part would be suitable for a web app. On the other hand, when the mail carrier delivers the mail (or tries to), we can expect they’ll change the status for that mail. A mobile app is best for that operation, as they could update items on the spot.
-
3. Is this model limited to postal mail systems?
No; there are many companies that perform all manner of deliveries today. They too need such an application. We could also use this database to store information for a shipping company or department. In fact, any kind of job that includes any kind of item delivery could use this data model. Even drone-powered pizza deliveries are an option. 😊
The Data Model
The data model consists of three subject areas:
Countries, cities & officesLocationsMails
We’ll present subject areas in the same order they’re listed.
Countries, Cities, and Offices
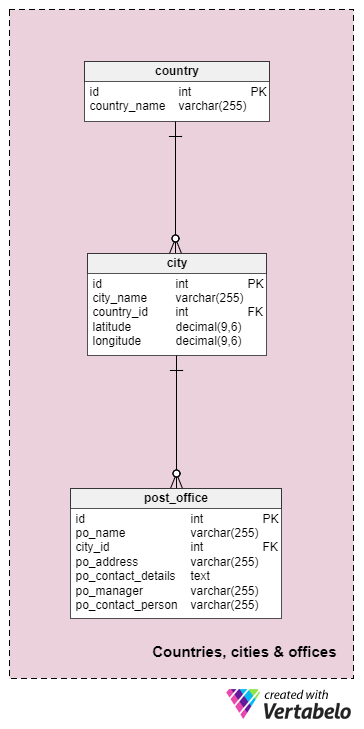
The first subject area I’ll describe is Countries, cities & offices. It’s not the most important one in the model, but it is a prerequisite for the other subject areas.
Each distinct post office is stored in the post_office table. For each office, we’ll have:
po_name– A name that UNIQUELY designates that post office.city_id– References thecitydictionary and denotes the city where this office is located.po_address– The physical address of the post office.po_contact_details– All contact details, in textual format, for that office. We could use a different structure here if needed. In that case, we’d use a dictionary to store all possible contact detail types and then create a relationship between that dictionary and this table.po_manager&po_contact_person– The first and the last names of the postmaster or manager (who is in charge of that post office) and a contact person. Again, we could also use a dictionary with roles and a many-to-many relation between that dictionary and this table to store this information.
The remaining two tables in this subject area are dictionaries used to store the city and the country where each post office is located.
For each city, we’ll store a city_name, the ID of the relevant country, and the office’s latitude and longitude. Notice we’re using “latitude” and “longitude” and not “lat” and “long”, which are often used. The main reason is to avoid using the reserved word “long”. Everything would work even if we use reserved words, but it’s good practice to not use them. We can avoid stupid mistakes later (e.g. when writing queries) when we don’t use reserved words.
The city dictionary is simple. It stores UNIQUE country_name values. We could store all the countries if we want to, but we’ll probably store only those where our service operates.
Locations

The Locations subject area contains all information needed to store and describe locations and the services we’ll provide at these locations. Locations, in this model, are all the physical locations used by our service, from household mailboxes to mail drop-off points to the local and central post offices. Of course, we’ll have different types of services at different locations. While we just use our mailbox to send or receive our mail, we can buy stamps and other materials and services (like special delivery) in an office. Some post offices provide other services as well, such as sending money orders, buying stamps for your collection, etc.
The central table of this subject area is the location table. This is where we’ll store every single location related to our company. Therefore this table will store post offices (again) as well as mailboxes and other drop-off points. We will also relate each mailbox or drop-off point to an office. This will let us track which post office is in charge of which mailbox; this will be handy if there is an issue related to that location. We can also organize mail pickup and delivery because we will know which office is responsible for delivery and collection for each location.
For each record in this table we’ll store:
location_name– A UNIQUE name for that location.post_office_in_charge– References thepost_officetable and indicates the office responsible for that location. This is a mandatory attribute, so we’ll always know which post office is in charge of which “object”.post_office_id– The ID of the post office. This attribute will contain a value only when thislocationis also apost_office. I want to store all “objects” and “offices” in one place so that we can reference them from the same table.description– Additional textual descriptions, if any.
Next, we’ll store services and relate them with locations.
The list of all services we provide or have provided is stored in the service catalog. At some locations, mail can only be sent (and only with the stamps already on it); at others, maybe we could also buy stamps; at others, maybe we could also send packages, etc. For each record in this table, we’ll store the UNIQUE service_name, an additional description, and the is_active flag that denotes if we still provide that service.
We also need to relate the location and service tables. We’ll do this in the service_available table, which allows us to define what services are available at each location. This table contains the UNIQUE location_id – service_id pair as well as additional descriptive details, if needed.
Next we’ll define how we handle mail at various locations. We’ll use four tables for this. Two are dictionaries: the collecting_catalog table and the processing_catalog table. These tables are almost the same in structure, so I’ll describe them together. The remaining two tables, collecting_option and processing_option, store combinations of locations and “handling” options. Again, these tables share almost the same structure, so I’ll describe them together.
Both dictionaries have their primary keys (id)and a UNIQUE option_name. These are the names of the processes that are used at all our locations. I could use only one dictionary here, but I wanted to separate these two because they refer to different parts of the process. The collection_catalog lists all the ways a sender could give us mail. This could be via personal mailbox, at a collection point, or by way of an employee in the office. The processing_catalog stores all the internal activities we perform on the mail.
For the same reason, I’ve also used two tables to denote all options associated with a certain location. Both will store the UNIQUE pair of location_id – collecting_catalog_id / processing_catalog_id and any additional details.
The last two tables in this subject area store relations between locations and the nature of these relations.
All possible types of relations that could be assigned to a pair of locations are stored in the connection_type dictionary. This lists UNIQUE type_name values like “daily delivery”, “checking weekly (every Monday)”, etc.
The location_connection table contains a list of location pairs (location_from - location_to) and a reference to the connection_type dictionary. All three attributes in this table together form the UNIQUE key. We need all three attributes because two locations could have more than one type of relation. For example, one could denote delivery frequency between the two locations and another could denote the type of the vehicle operating between them.
Mails
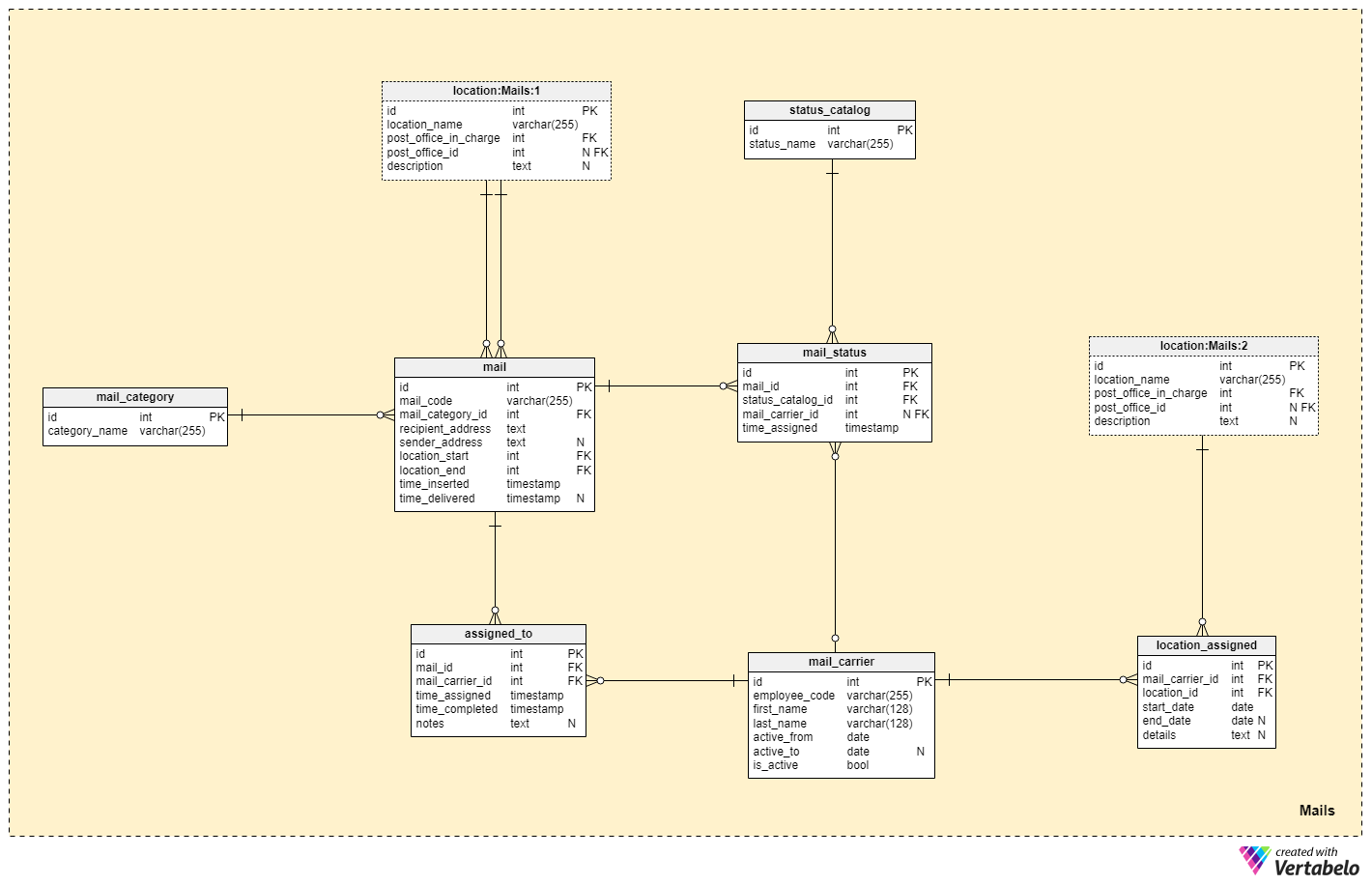
The final but most important subject area in this model is Mails. This where we’ll store everything related with each piece of mail, from its details to every step in the handling and delivery process.
As you might guess, the central table in this subject area is the mail table. It stores all important details of every mail item. These details will be inserted when we get the mail, either when a customer hands it to an employee at the office or when it is delivered to the office by a carrier. For each mail item, we’ll store:
mail_code– A UNIQUE code generated for each item.mail_category_id– References themail_categorydictionary and denotes the type of mail, e.g. by size, weight, or both.recipient_address– Self-explanatory.sender_address– The address of the person who sent that item. This address will be used to return the item if it can’t be delivered to the recipient.location_start&location_end– Are both references to thelocationtable. When we insert a record into this table, we will know the starting location (our post office or a mailbox) and the location closest to the recipient.time_inserted– When this record was inserted in the system.time_delivered– When this mail was delivered to the recipient. This value is NULL until the mail is delivered. If the item was returned to the sender, the value will stay NULL.
We have already mentioned that we’ll reference the mail_category dictionary. Aside from the primary key, this table has only one attribute, category_name, which contains only UNIQUE text values.
Nothing happens without a mail_carrier, so let’s add a table for them. Each record will contain:
employee_code– A UNIQUE code assigned to each mail carrier in our company.first_name&last_name– The first and the last name of the mail carrier.active_from&active_to– A range of time when that mail carrier worked for us. The second attribute will be NULL if the mail carrier still works for our company.is_active– If this mail carrier is still active or not. When we set this flag to “False”, we should also set theactive_tovalue.
Each mail carrier is usually assigned to one or more locations. We’ll cover this using the location_assigned table. For each record here, we’ll store:
mail_carrier_id&location_id– The IDs of the mail carrier and the location where they are assigned, respectively.start_date&end_date– The period when this data was valid. The second attribute will be NULL if the assignment is current.details– All additional details, in textual format.
We can expect that mail items will be grouped and then each group will be assigned to a mail carrier. We need to know who handled each mail item and when, so we’ll use the assigned_to table. For each mail item, we’ll store:
mail_id&mail_carrier_id– The IDs of the mail item and the carrier that was assigned to it.time_assigned– When this item was assigned to the carrier.time_completed– When the carrier finished the assignment. This could be because the item was delivered or because it was assigned to another carrier.notes– Any additional notes related to that specific assignment.
The final two tables track all the steps of the handling and delivery process.
First, we’ll need a list of all possible statuses that could be assigned to a mail item. This list is stored in the status_catalog dictionary. Once again, we have only the id attribute and the UNIQUE textual value, status_name. Statuses include all possible events that could happen during the process, from “new mail in the system” to “mail delivered”.
The mail_status table will record all events related with each mail item. We’ll store references to the “mail” and its related status, the ID of the carrier who inserted that status, and when the status was assigned. Only the mail_carrier_id is NOT NULL, and that will be when the status was assigned automatically or by some other employee.
It’s important to point out that this model is designed for sending registered mail. It could be also used to track unregistered mail. In that case, we should mark mail as unregistered (assigning the appropriate id from the mail_category table), thus avoiding unnecessary checks.
What Would You Change in This Data Model?
The model presented today could be used to track activities in a mail delivery company. It contains the data background for the most important functionalities in this type of system. Would you add something to this model? What would you change? Please tell us in the comments.
