

Don’t suffer from blank sheet syndrome when you have to create a new data model. Explore the ready-to-use database model examples we offer here and you will surely find the inspiration you need to kickstart your design.
When you have to create a data model to solve a need common to many businesses, it is almost certain that many designers have done it before. You can learn from what they have done so that you don’t have to reinvent the wheel. The good thing is that many data modelers share their database diagram examples to help their peers simplify their work.
Database design sites, such as the Vertabelo blog, are a virtually endless source of database model examples to use as a starting point for your work. Whether you need to create a database for a payroll system, a generic model for audit logging, or a subschema to support a multi-language application, a pre-designed model can save you time and effort.
Throughout this article, you will find plenty of database diagram examples that can be very useful in your work as a database designer. And if the model you need to create does not fit any of these examples, you’ll also find references to other resources that will help you find what you need.
7 Common Data Models to Fire Up Your Database Design
1. Payroll Data Model
This example illustrates, among other things, the usefulness of dividing a schema into subject areas.
A payroll data model should be designed to easily calculate the salaries of an organization's employees. In small companies – with no more than a couple of dozen employees – salary calculations are simple. In these cases, a data model would have one table for employee data, one for salary data, and a few more lookup tables. But in data modeling, it’s preferable to think big. Try to design with foresight so that the model does not become obsolete as the organization grows or its structure becomes more complex.
In this payroll data model example, Employees and Salaries are two large subject areas that are clearly identified by different colors. The employee subject area includes the employee table along with its subordinate tables: employment_terms, departments, job_titles, etc.
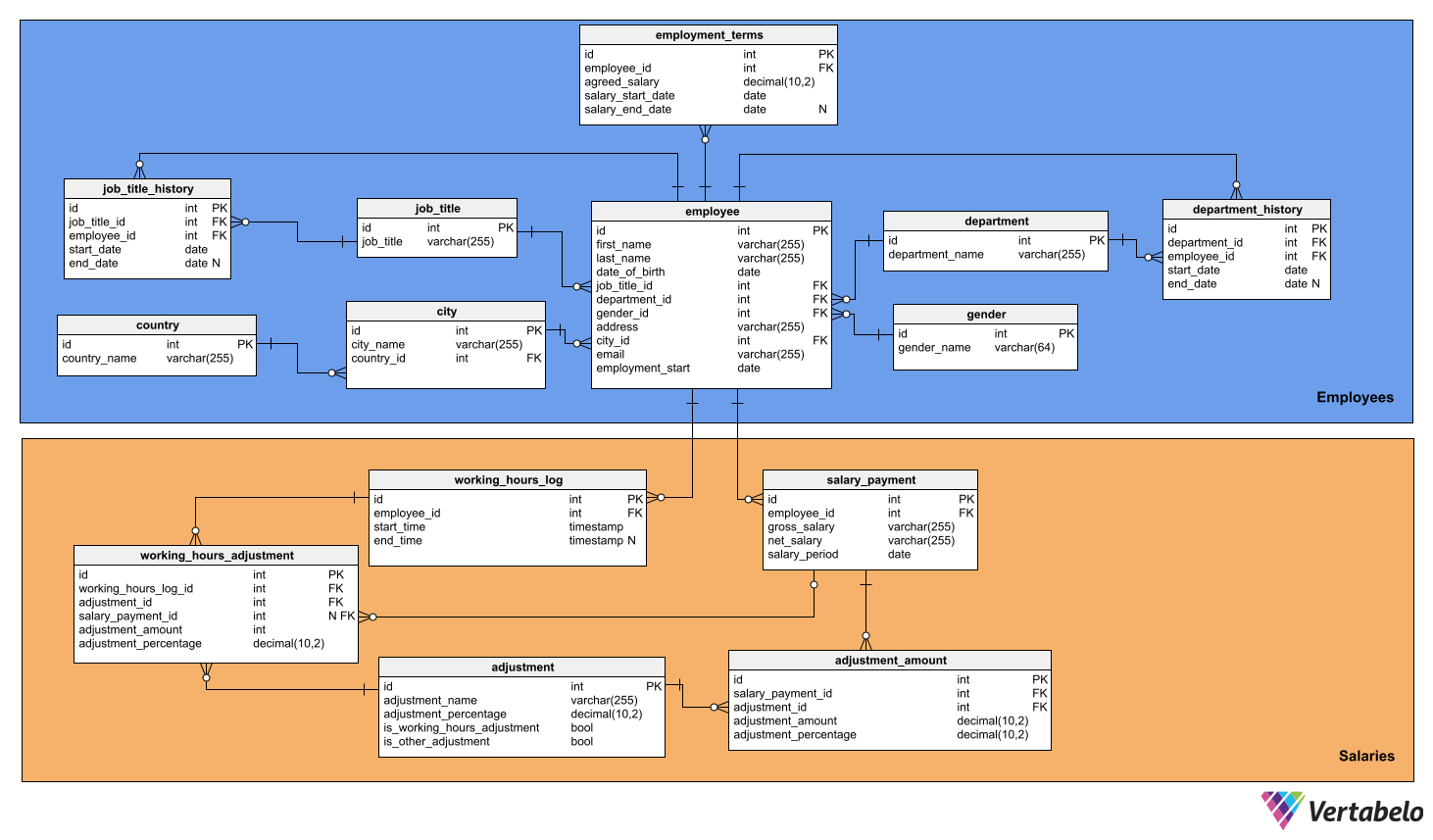
The two main subject areas in this diagram group the tables associated with Employees and Salaries.
Knowing that employees can change their job title and department any number of times while working for the same company, the schema includes two trail tables so that the change history is not lost. These are job_title_history and department_history. To find out the current job title and department data for an employee, you could use these two tables to query the most recently dated rows for the employee. However, the designer preferred to add a slight degree of redundancy to simplify the queries by adding the job_title_id and department_id columns directly into the employee table (besides including them in the corresponding history tables). Such subtle violations to normalization rules are often accepted because they make writing SQL queries easier.
Remember, it is a good practice to document your design decisions by using text notes in data modeling.
2. Audit Logging Data Model
The different database diagram examples that you can use for audit logging basically boil down to three models that provide different balances between versatility and ease of use.
Audit logging is an important feature when you need to keep track of every modification and every deletion that is made to a table. There are specific logging solutions that require the use of proxies or middleware between the application and the database; they may also require parallel databases, created exclusively for log storage. These solutions tend to be expensive, but they are justified in situations where logging is a legal requirement or a first priority for the application.
But in cases where logging is only required for occasional querying of historical data, you can opt for a database design for audit logging that can be handled directly by the application. There are different data model options for audit logging. But you should be aware that all of them introduce some complications for model maintenance, logging data, or querying historical information.
The first option is to add columns for version data to every table where an audit trail is required. Any deletion or modification operation performed on these tables is transformed into an insert that increments the version number of the affected row. It also records the user, date, and operation performed. This option does not require additional tables for logging, but it ruins the beauty of the model, forcing you to dispense with such things as natural primary keys or referential integrity. It also introduces a difficulty when you only want to access the current data (i.e. the latest version of each row) in the table.
The second option is to create shadow tables for each table that requires an audit trail. This option doesn't ruin your model, but it forces you to modify the shadow tables every time you make a modification to the main tables of your schema – or to add new shadow tables each time you add a table to your model.
The third option is to use generic logging tables. This option is the most conducive to your data model’s beauty and integrity, but it has two disadvantages:
- That all data stored in the audit trail must be converted to a generic data type (e.g. a large enough VARCHAR) or serialized as XML or JSON objects.
- Querying the information stored in the generic tables of the audit trail is quite a difficult task.
3. Multi-Language Data Model
If you need a database design for multi-language applications, you also have three options to choose from. They have varying degrees of versatility and ease of use. The basis for multi-language support is a data model prepared to record translations of all application texts into all languages that the application must support. Those translations add information that has to be stored somewhere. The options for this storage are similar to those we saw above for the audit log:

- Add columns for texts in different languages to each table that needs translations.
- Add shadow tables with translations as needed.
- Create a subschema with special tables for translations with IDs that can be referenced from the main tables.
The pros and cons of these three options are also similar to those of the audit log – i.e. the more user-friendly the option, the less flexible it tends to be and vice versa.
The most advisable option from a database design point of view is the translation subschema. This subschema uses a translation table that is related to a language table and two other tables for column and table information. Although this schema requires some additional work to obtain the translated texts for each language, it provides enough flexibility to be able to add new languages or incorporate new fields and tables to the translation schema without changing the database structure.
To simplify access to the translated data, the designer added an abstraction layer with views that present the same structure of the main schema tables but replace the original texts with the translated ones where appropriate.
4. Library Data Model
This data model exemplifies the technique of splitting the generality and instances of an entity. The entity we’re talking about in this case is book.
Any library can benefit from a software system that allows it to manage its book catalog, membership list, and book loan records. Such a software system should be based on a library data model that includes tables for storing book, library, member, and loan data. The proposed data model divides the schema into two subject areas: one for books and libraries and one for members and loans.
The subject area for books and libraries includes the necessary tables to catalog the books by category, author, and publisher (among other data). Since there can be several copies of the same book, the book table has a subordinate book_item table where each row represents a copy of a book with a unique identifier. In this sense, book acts as an abstract entity, while book_item represents the instances of a book, each of which is associated with a real-world element (i.e. a printed copy).
The model supports multiple libraries. The relationship between book_item and library lets you determine the physical location of each book copy.
The second subject area of the library data model is smaller. It contains only a table to store records for library members, a table for loans – which relates the member table to the book_item table – and a lookup table with all possible loan statuses.
The model is designed to catalog books according to a wide variety of criteria; this will facilitate searches. But its versatile design makes it equally useful for managing even a small library, where such a wide range of classification criteria may not be needed.
5. Learning Management System Data Model
A database design for a learning management system should include, at a minimum, tables to record course and student information. And it must also include a relationship between them so we know which student is enrolled in which course.
To give more functionality to the model, the Courses entity is divided in two (similar to the book entity in the library data model). On the one hand, we have the general Courses entity, which contains the immutable course data (e.g. title, category, and description). On the other hand, we have the subordinate entity CoursesByCycle, which represents each instance of a course within a teaching cycle. This entity contains the course information that varies from one academic year to the next: start/end dates, exams, enrolled students, teachers, etc.
This separation between immutable and mutable data is what allows us to add tables that store student attendance, exam results, and any other information that a learning management system may require. We can also relate those tables with the proper entity, depending on its mutability.
6. Hotel Booking System
To reuse generic data models, the model should preferably be logical rather than physical. This is so that it does not contain characteristics of a particular RDBMS. Vertabelo allows you to reuse logical models to create physical models for any database engine.
The following hotel reservation data model uses Vertabelo's functionality to implement inheritance relationships between entities. With this functionality, we define the parent entity Rooms and three child entities – Suites, Singles and Doubles – that inherit common properties and add properties that distinguish them from their siblings.
With its logical database diagrams, Vertabelo lets you define inheritance relations such as the one depicted here between the mother entity (Rooms) and the three different child entities: Suites, Singles, and Doubles.
When implementing this model on a particular database engine, all you need to do is ask Vertabelo to generate a physical model and choose the target database engine. In a matter of seconds, the physical model will be created and it will be ready to generate a database on the chosen RDBMS.
7. Data Model for User Authentication
Many designers (believing that it is an easy task) choose to reinvent the wheel every time they have to create a data model to store user authentication data. The result is databases that can be easily attacked by hackers. Such databases are serious security risks and create the possibility of exposing sensitive user information.
The ideal way to avoid such risks is to adopt a set of universally accepted security best practices. For an example, check out our article on how to store authentication data in a database.
The first rule of security is not to store passwords in the database, even in encrypted form. If the database exposes encrypted data, there is a chance that someone will decrypt it. The alternative, as you can learn by reading the aforementioned article, is to store only the password hashes. Other best practices include avoiding obvious table names, such as user. By reading the article, you will learn about many other important considerations to take into account when designing a data model for user authentication.
Other Ready-To-Use Database Diagram Examples
The Vertabelo blog offers a lot more database diagrams for you to use. Check out the ones listed below and see if you can borrow some ideas for your modeling work:
- An Integrated Transport Data Model
- 911/112: An Emergency Call Service Data Model
- A Public Opinion Agency Data Model
- 7 Tips for a Good ER Diagram Layout
- Where to Find Database Diagram Examples
- A Detailed Guide to Database Schema Design
- Database Design for Online Survey Systems
More Data Modeling Resources
The examples provided above are just a few of those that can be found online. For more examples and tips on creating database diagrams, the discussions on Stack Overflow are very useful. I recommend this case, where a designer asked his peers for validation on an ERD for a matchmaking app or this one for a database design for a review and ratings site. A specific search for various database design topics on Stack Overflow will provide you with even more information.
Finally, if you prefer reading books, the following titles have examples of pre-designed diagrams with detailed explanations by expert designers:
- Beginning Database Design Solutions: A concise introduction to database design concepts that also offers plenty of design examples.
- Beginning Database Design: From Novice to Professional: A guide to learning how to design databases, with numerous examples to help you avoid the many pitfalls that entrap new and not-so-new database designers.
- Database Systems: Design, Implementation, and Management: A solid foundation in database design and implementation, with plenty of practical examples that you can use for your own designs.
With such an abundance of pre-designed templates for different purposes, you will rarely have to start your designs from scratch. Just browse through the many examples in this article and you’re sure to find something that will give you a head start.
