

With the latest release of Vertabelo in 2021, we have overhauled the UI for a better experience in database modeling. We’ve also added a lot of new features requested by our customers.
We’re happy to announce we now support the latest versions of PostgreSQL and MS SQL Server. You can now define partitions, specify data types for sequences, and add identity columns in PostgreSQL. Similarly, you can create DDLs for the latest versions of MS SQL Server.
This article tells you how to enable some of the new features for the newly supported PostgreSQL versions. Please note the newer versions of PostgreSQL and MS SQL Server are available for all of Vertabelo plans: Basic, Premium, and Team. See the details on Vertabelo’s pricing page.
1. Table Partitioning in PostgreSQL
First, let’s look at the much-awaited PARTITION BY clause, which is a tremendous help during the database design process. Select the table you want to add or modify the partitions for. Go to the right-hand panel and navigate to “Additional properties”. You’ll see the following three fields grayed out, among other things:
PARTITION BY- Partition of
- Partition bound
To enable any of these options, just toggle the Set option on the side of the text box.
There are two ways to partition in PostgreSQL. You can use a PARTITION BY clause, providing the name of the field you want to partition the table by as shown in the SQL script below:
CREATE TABLE catalog ( id not null primary key, isbn varchar(32) not null, title varchar(64) not null, authors json not null, release_date date not null, ) PARTITION BY RANGE (release_date);
Alternatively, you can use a combination of PARTITION OF and PARTITION BOUND fields.
CREATE TABLE catalog_y2002m02 PARTITION OF catalog
FOR VALUES FROM ('2002-02-01') TO ('2002-03-01');
Using any of the above-mentioned additional properties, you can partition your PostgreSQL tables and cruise through your database modeling journey smoothly.
2. Identity Columns in PostgreSQL
PostgreSQL, like other database engines, allows for an auto-increment column called IDENTITY. You can have multiple identity columns for the same table. You can also use identity columns as primary keys.
With Vertabelo’s latest release, you can now set the identity column in the column properties of any column of the table. To do so, toggle the three dots adjacent to the delete icon in front of the column. Once you do that, you’ll see the “Identity” and “Identity options” fields you can use in the DDL.
3. Macaddr8 Data Type in PostgreSQL
Vertabelo supports all the PostgreSQL data types, even the minor ones. In the newest version, the Macaddr8 data type has been added.
It is so rarely used, and you may not see it in the “choose column type” popup. To use this data type in Vertabelo, you have to specify it manually. Vertabelo will validate the name of the data type; it will not throw any warnings or errors at you.
4. Sequence Data Type in PostgreSQL
You can now specify the data type for a sequence. This is done by using the additional property “Data type” in the sequence properties panel (see screenshot below).
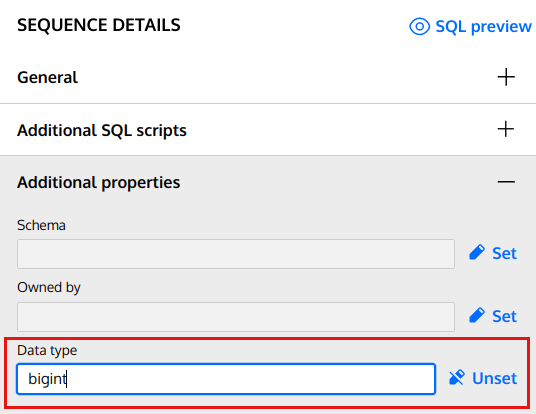
When this property is set, the "AS ” statement is generated in the final DDL as shown in the example code below:
CREATE SEQUENCE my_sequence
NO MINVALUE
NO MAXVALUE
NO CYCLE
AS bigint
;
5. Support for MS SQL Server
Support for MS SQL Server 2017 and 2019 has been added to Vertabelo. However, you may not need to make any changes to your DDL even if you upgrade to a newer version since there are no substantial changes to the generated DDLs. While Vertabelo supports the latest versions, we also continue to support older versions of MS SQL Server, such as 2012, 2014, and 2016.
6. Where Database Versions Are Used in Vertabelo Modeler
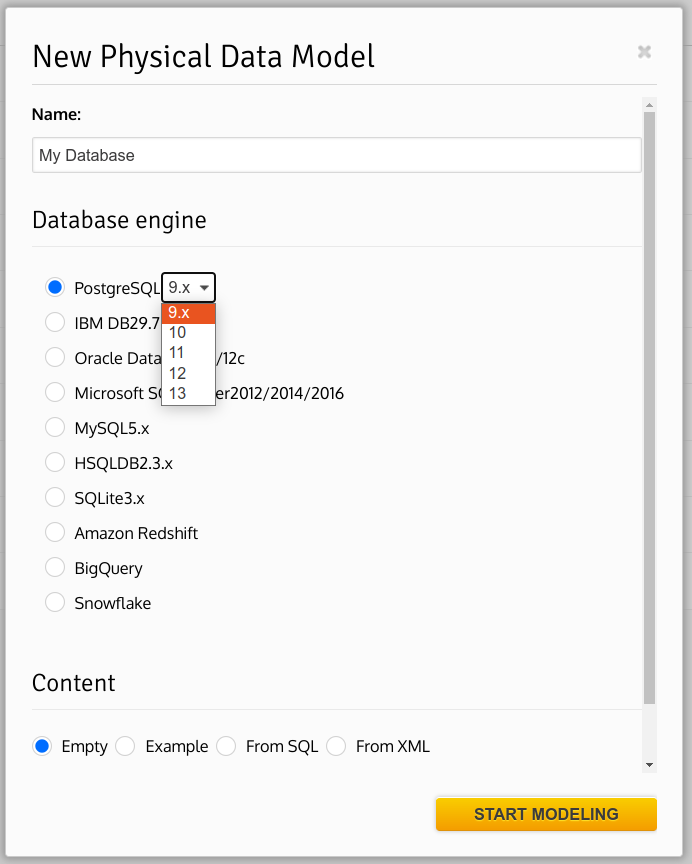
As a reminder, database engine versions are used in Vertabelo Modeler in three places.
- When creating a new physical database model:
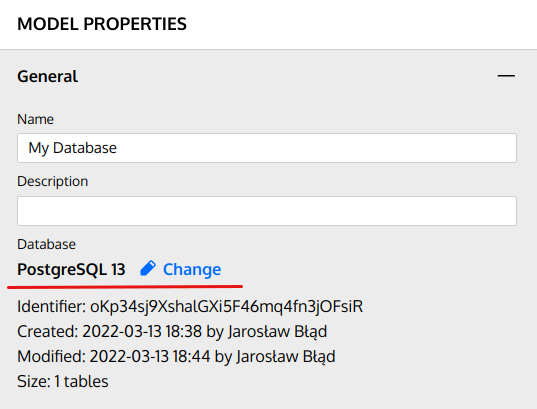
- On the physical database model itself. In the “Model Properties” panel, there is an option to change the database engine or the database engine version:
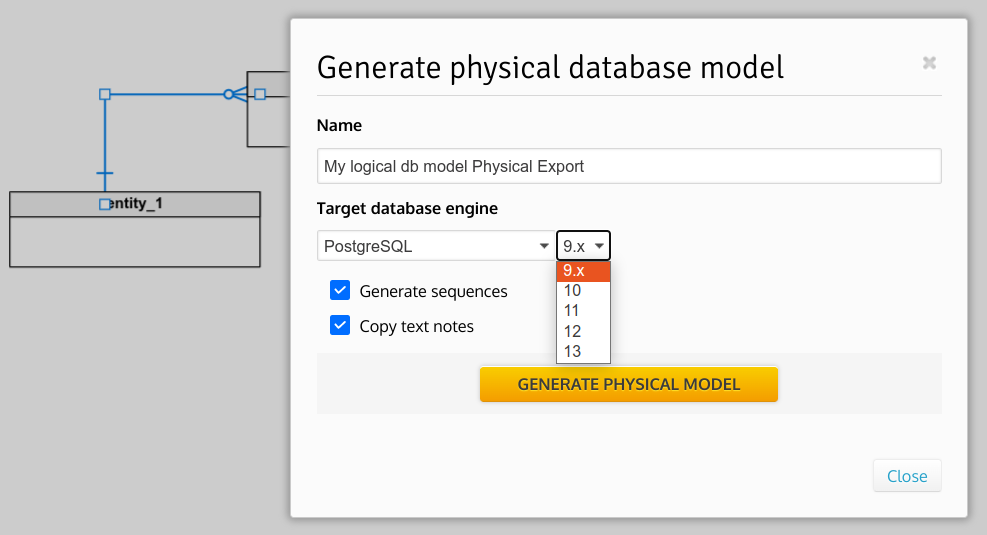
- When generating a physical model from a logical one:
7. What’s Next
The Vertabelo team works tirelessly to bring the latest database modeling features to you. Of course, we always strive to support all the popular database and data warehouse engines you need for working with data models. Vertabelo already supports some of the most widely used data warehouse platforms, such as Snowflake, Redshift, and Google BigQuery.
To keep fulfilling our pledge, we are rolling out support for MySQL 8.0, MariaDB 10.0, and Oracle 19c as well as 21c in 2022. Vertabelo provides the most up-to-date capabilities in an ERD tool while continuing to support older database versions.
