

Ever use Craigslist or some other online classified ad website to sell or buy something? Did you wonder how it worked? In this article, we talk about how an online classifieds data model can be designed using a relational database.
Online classified ads (such as Craigslist) offer a place to buy or sell new or used products, advertise services, and connect with various people. In this article, we’ll see how to design an optimized, performance-friendly database model for such a platform.
What Does It Take to Run an Online Classified Ad Platform?
When I think of developing a classified advertising platform, I immediately think of the huge volume of data involved. Just look at the numbers. Craigslist, which operates in more than 270 cities in over 50 countries, gets 1.5 million new posts every day. Add to this the fact that posts are viewed many times and that Craigslist carries out innumerable search requests – many of which happen simultaneously – and you can see the kind of performance that we’d need!
Designing such a database is almost a nightmare, especially when using a relational database like Oracle. However, Oracle has included some beautiful features that allow developers to build an efficient and smart application while still keeping data in a relational format. XMLType is one of these features. I will explain its usage later in this article; for now, let’s concentrate on the requirements of this data model. What key points should we keep in mind?
- Besides huge data volumes, we must consider the many types of data we’ll store. The data captured in selling a car is definitely different than that for renting a house. Most of the time, the fields will vary within the same category; for instance, the application should not capture the same set of data fields for a bike as it does for a motorcycle. The app must be able to support a wide range of products and services while allowing granular details in the posts. Also, when the platform gains popularity, the database should be able to support the growth.
- Online classifieds are dynamic. Data fields keep changing with time. For example, a few years ago, it was important to note which type of keypad a mobile phone had. Once smartphones hit the market, this information became largely irrelevant. The list of data fields keeps evolving, and no architect wants to change the data model every time a new requirement comes in.
- Data archival should be seamless. Usually such portals keep the previous 30 or 60 days of data for display to end users. Older data is archived in a data warehouse and is made available only to business analysts or for reporting purposes. Data archival should be seamless, never degrading the application’s performance when the archival process is in progress.
- Searches should be local. A user in London will usually prefer to see search results in and around London. Therefore, searches must be address- and postal-code-driven and should display results in the user’s vicinity unless they explicitly request results for another location.
The Data Model
Managing Buyers, Sellers, and Users
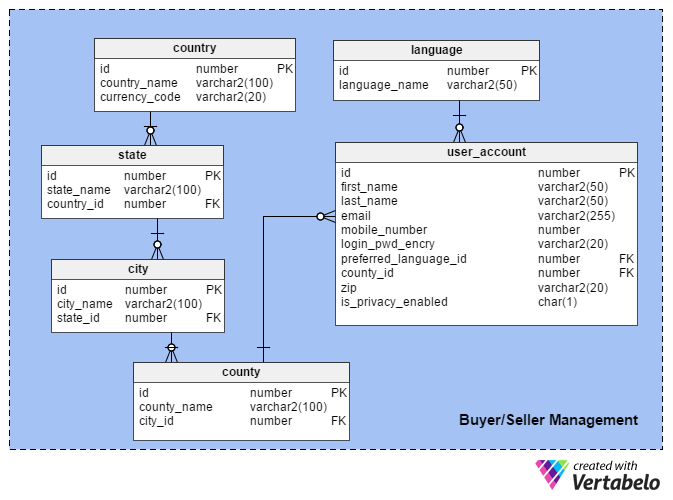
Users can be buyers, sellers, or advertisers. We cannot distinguish users by their roles here because a seller can become a buyer and vice versa. Of course, this also applies to advertisers; they may use their account for more than one purpose. Therefore, capturing users’ roles is not needed for this application.
The critical information about a post is its tagged location (county_id and zip). The application inherits this information from the user_account table and binds the post with the location of the user who publishes it.
The user_account table holds users’ preliminary details, which are captured during the registration process. Most of the columns in this table are self-explanatory, except the following:
preferred_language_id– Holds the language that users prefer to communicate in. This column is important in multi-lingual areas where people may feel hesitant to contact sellers unless they have a common language.county_id– Address fields (i.e. country, state, city, and county) are stored in a different way in this model. This column not only represents the county, but the city, state, and country of the user. Geographical data is usually fixed, so we can pre-populate these tables immediately before making the application available in a new location.zip– You might be wondering why this column’s information is not included in thecountytable. There are many counties that have multiple ZIP or postal codes. Therefore we cannot keep this column in the county table.is_privacy_enabled– This is a security feature in the application. Many users do not want to have their details ( e.g. phone number or street address) visible in their posts.
The county, city, state and country tables, as their names suggest, hold details about each address field. All the columns in these tables are self-explanatory.
Managing Categories and Subcategories
Posts are organized into various categories and subcategories. As an example, ‘Electronics’ is a category, and ‘Mobile Devices’ is one of its subcategories. Users are allowed to publish posts in any category or subcategory after they have registered.

The category table holds all categories in hierarchical format, going from root level to leaf level by means of recursive relationships. The columns are:
id– Gives a unique number to each individual item. This is the primary key of the table.category_name– The name of the category.parent_category_id– Establishes the hierarchical relationship of the various details.maximum_images_allowed– The maximum number of images allowed per post in this category. (This applies to leaf-level categories only; it is NULL for other categories.)post_validity_interval_in_days– The number of days that the post will be active (i.e. displayed to users). This column also helps determine which posts need to be archived. (This attribute applies to leaf-level categories only; it is NULL for other categories.)
We can easily extract a complete list of the hierarchy of all categories and subcategories by using WITH and recursive CTE queries. If you are using Oracle, you can also use the CONNECT BY clause.
The property table holds a list of the attributes used to publish posts under a particular category. For example, while posting an ad to sell your car you may be asked to fill in its make and model, mileage, fuel type, body color, and so on. This table keeps a list of all such standard attributes for various categories. The columns in this table are :
id– The primary key of the table.category_id– The applicable category.property_name– The property name, as it is shown on the platform’s user interface.property_unit– The measuring unit for the property. For example, the mileage of a car is measured in kilometers or miles.is_mandatory– Whether the property is mandatory for posts in this category.screen_control_id– A developer-specific column that signifies which type of UI control is to be rendered – i.e. a drop-down menu, text box, radio button, etc.possible_values– Controls like drop-down menus and radio buttons display a list of possible values. These values are stored in this XMLType column.
Adding and Retrieving Category Attributes in the Property Table
Below, I am adding the ‘Car Manufacturer’ attribute to the ‘Car’ category:
insert into property values (1, (select id_category from category where category_name = 'Car'), 'Car Manufacturer', null, 'Y', 1, ''); Toyota Hyundai Honda Suzuki Kia Nisaan
Retrieving a list of these values is also easy. I’ll extract a list of all ‘Car’ category attributes and their possible values in tabular form using this code:
SELECT xt.* FROM property x, XMLTABLE('/values/value'
PASSING x.possible_values
COLUMNS
"VALUE" VARCHAR2(100) PATH 'value'
) xt where x.id_category = (select id_category from category where category_name = 'Car');
Managing Posts and Their Attributes
We have now arrived at the innermost part of this data model. Publishing posts is the core functionality of the application.
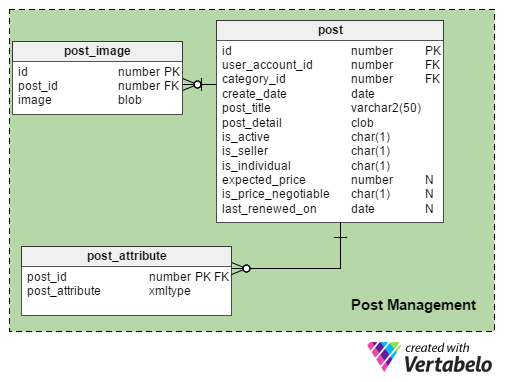
The post table holds details about individual posts. Its columns are:
id– A unique number assigned to each post.user_account_id– The user who has published the post.category_id– The category a post is published under.create_date– The date the post was published.post_title– The short text title of the post.post_detail– The post’s entire text, stored in a LOB column.is_active– Whether the post is currently active.is_seller– Whether the post is about selling or buying. If this attribute is set to true, then it is a sales post (which includes advertisements); if it is false, it relates to buying.is_individual– Whether the post was published by a private individual or a dealer.expected_price–The expected price for the product or service. This value is optional, and thus this is a nullable column.is_price_negotiable– If the quoted price is negotiable or firm.last_renewed_on– Many times, people prefer to re-publish the same post instead of creating a new one. When a post is re-published by the user, the date is accordingly updated in this column. Also, the post’s archival eligibility is determined using this column instead of thecreate_datecolumn.
The post_image table holds images that are attached to posts. The maximum number of images that can be attached to one post is determined using the maximum_images_allowed column from the category table.
Logging Key Features of Individual Categories
All attributes captured for a post are stored in the “post_attribute” table. The columns for this table are:
post_id– The ID of the post the record is associated with. There is only one record for each post, so I have made this the primary key for this table.post_attribute– Holds values for all attributes in XML format.

For example, suppose there is a post about selling a used car. The post_attribute XML would look like this:
Hyundai i20 2009 Petrol Metallic Grey
Why Use XML Instead of EAV to Store Individual Attributes?
The EAV (Entity-Attribute-Value) model is simple to implement, very flexible, and highly reusable. Even so, I don’t advise using it to store attributes for individual posts. Why not?
- The EAV model looks very promising at first, but its performance degrades over time. The data in this type of application is always increasing. The moment it grows beyond a certain size, data extraction often becomes less efficient. And since there is no upper boundary for data in users’ posts, I don’t want to use the EAV model.
- Reporting EAV data is difficult in terms of complexity and performance.
- Maintaining data integrity is also a problem. We can store all types of values in a VARCHAR2 column, for example. But we cannot impose UNIQUE or CHECK constraints.
XMLType addresses all these concerns very well, and thus I have chosen to use it.
Adding a Reminder Function
Suppose you are looking for a 32” LED TV in the vicinity of Brooklyn, New York. So far, you have not found a suitable match. You can put a reminder in the application that would notify you when relevant posts are published. This reminder feature is provided by the post_alert table, which has these columns:
id– The primary key of the table.user_account_id– The user who requested the notification.create_date– The date when the reminder was registered.valid_for– The number of days the reminder is active. It expires when the sum of create_date + valid_for date is reached.category_id– Signifies which type of posts are to be monitored and when to send the notification.Search_context– This column holds the searchable text – i.e. a product name – that the user sets. The application will send a notification to the user as soon as it identifies this text in any posts in the selected category.

In Conclusion
We should always look at the bigger picture when we design a solution for any problem. This particular scenario is not only about storing data; it’s also about managing the consumption of stored data and the disposal of older data. Before you even begin the design process for such a data model, ask yourself:
- What are the data and traffic volumes likely to be?
- What is the lead time on adding or removing a category attribute?
- What is the standard life of a post? When do posts get archived? What is the permissible downtime during the archival process?
- What changes will be required to make the application available for a new city or country?
Please feel free to share your views in the comments section.
