

There are a number of ways to contact someone these days, right?
We have various phones: mobile and landline, personal and work. We have different addresses – residential, mailing, billing, business, etc. – and likely several email addresses, too. Don’t forget Skype and various messaging apps. Now add in LinkedIn and Facebook –which by the way, both have their own messaging elements.
Not that long ago, many of these didn’t exist. So you can pretty much guarantee that in a few years, we’re going to have some new way of contacting people and organizations.
Can we model all of this contact info in such a way that we don’t have to change our database design when ‘the latest thing’ comes along? Read on to find out…
The Party Contact Point Model
In a word, yes. Databases can be designed to accommodate information we don’t even have yet.
I’m going to jump straight in and show you the solution, then I’ll describe how the pieces work together. I’m going to call the various ways of contacting parties contact points, though I have seen contact methods and even contact locations used.
Physically, all these contact points will be stored in a single table column, contact_point.contact_value. Think of a phone number, an email address, or a web address (URL) and you’ll understand why we can store them all here; they’re just strings (varchars) at this level. The differentiation is in the metadata. The only exception to this is the postal address, which will be described in more detail later.
The yellow tables on the left contain metadata, and the blue tables on the right contain business data.
The Major Categories
Although we have many ways of contacting someone, these ways actually fall into a small number of categories, or types. You’ll see what I mean when you look at the list below:
| Contact Point Type |
|---|
| Phone Number (landline) |
| Mobile Number |
| Fax Number |
| Email Address |
| Postal Address |
| Web Address |
| Pager |
In a sense, these are physically distinct. Of course, you can use a mobile phone to call a landline or another mobile. When it comes to voice calls between landlines and mobiles, the distinction is not that important. Still, we’re more likely to send a text (SMS) to a mobile than a landline.
But you’re not likely to deliberately voice call a fax number. After all, what are you going to say to it when you hear it, apart from ‘Oops, wrong number’? You are naturally much more likely to call with another fax machine, whether it’s physical or emulated. Neither would you send a letter to landline, or attempt to make a voice call to a postal address.
It’s important that we distinguish these types, because we interact differently with them. This will be especially true if your application has any sort of integration with communications services. It needs to know which type to interact with.
How Parties Use Contact Points
This is probably a bit more intuitive, a bit more in line with how we think about contact types. Here’s a longer list (but not an exhaustive one!) that will help you get a feel for these types:
| Party Contact Type (Contact Point Type) |
|---|
| Conference line (Phone Number) |
| Billing address (Postal Address) |
| Delivery address (Postal Address) |
| Direct line (Phone Number) |
| Holiday/vacation address (Postal Address) |
| Holiday/vacation phone (Phone Number) |
| Home address (Postal Address) |
| Home phone (Phone Number) |
| Home phone/fax (Phone Number) |
| LinkedIn profile (Web Address) |
| Main address (Postal Address) |
| Main email (Email Address) |
| Main fax (Fax Number) |
| Main phone (Phone Number) |
| Main website (Web Address) |
| Personal email (Email Address) |
| Personal fax (Fax Number) |
| Personal mobile (Mobile Number) |
| Personal pager (Pager) |
| Personal website (Web Address) |
| Secondary address (Postal Address) |
| Secondary phone (Phone Number) |
| Social media profile (Web Address) |
| Work address (Postal Address) |
| Work email (Email Address) |
| Work fax (Fax Number) |
| Work mobile (Mobile Number) |
| Work phone (Phone Number) |
The Postal Address – A Special Case
All of these contact point types are stored in a single field, with the exception of a postal address. This normally requires a number of lines (or fields).
There is a blog article here that proposes a simple, language-agnostic way to store postal addresses. If your requirements are rather basic – e.g. to print address labels pretty much as they are entered into the system – this approach will likely suffice. If your needs are more sophisticated, you will probably have to develop a different solution.
To get an idea of how complex addressing can be, have a quick look at this Schema for British Standard BS7666 Address Types. The standard comprises a number of parts covering Street Gazetteers, Land and Property Gazetteers, and delivery points. It does not differentiate between commercial or residential properties; between occupied, developed or vacant land; between urban or rural areas; or between postally-addressable entities and non-postally-addressable entities such as communications masts (towers). To achieve this, it introduces terms that most of us are probably not familiar with, such as Primary Addressable Object (PAO), which is the name given to an addressable object that can be addressed without reference to another addressable object. Familiar examples of PAOs include a building name or a street number. A Secondary Addressable Object (SAO) is given to any addressable object that is addressed by reference to a PAO. This might be the first floor of a named building.
To give us a visualization of this, I quickly reverse-engineered it into a UML modelling tool. Here’s what we get:
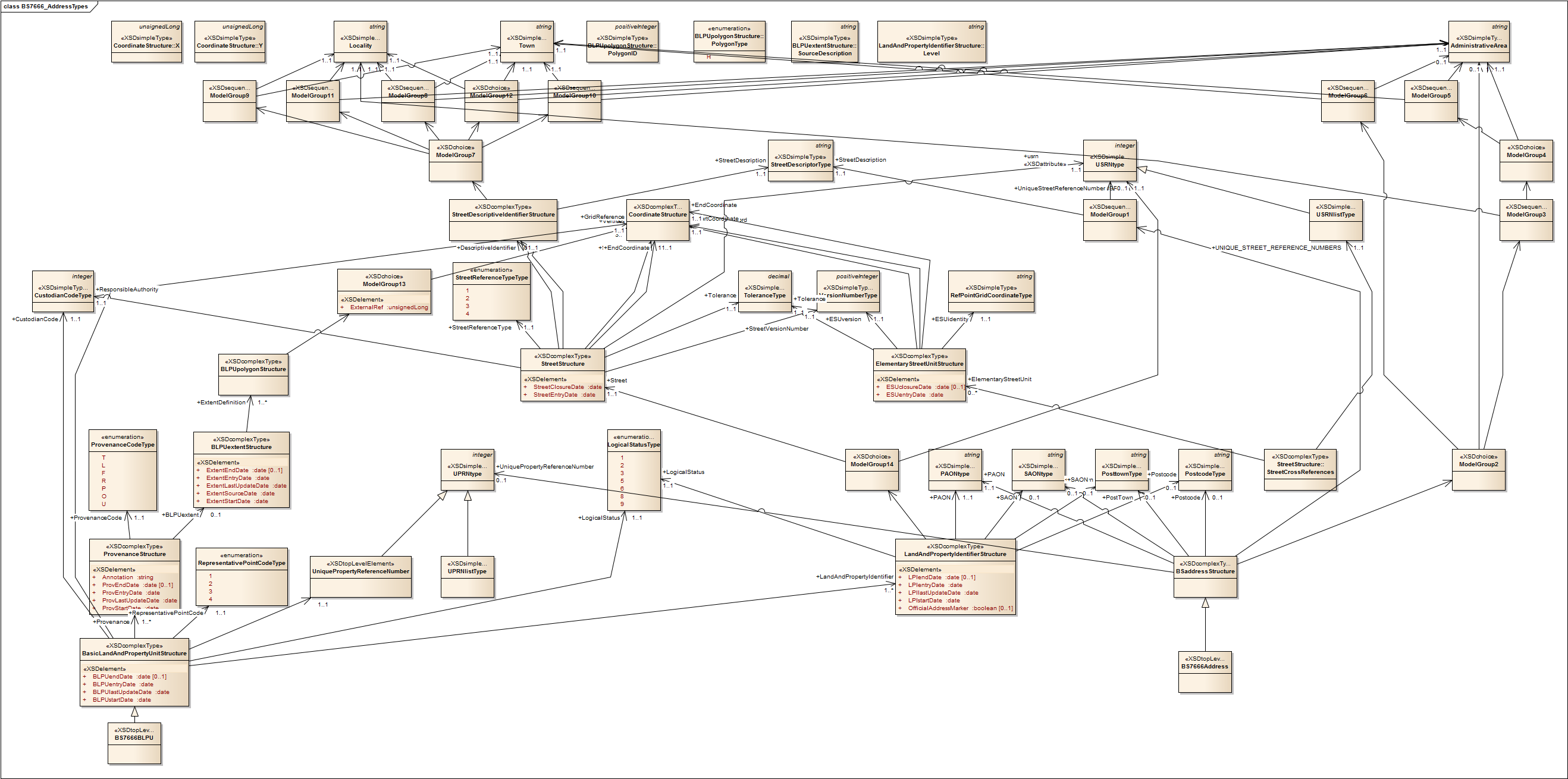
My point is that it can get pretty complicated and messy; addressing in some domains can be very complex indeed.
If you were to flatten this out into a single relational table, you’d get something like the following:
While this captures BS7666 address components, it doesn’t tell you how the model works. All the relational logic of the XML schema gets hidden away in application logic.
These two diagrams represent two data modeling extremes. But is there a middle way to model addresses?
It is indeed possible to have a relatively simple address model that is flexible and configurable.
Address Components
An address component is typically a line on an address label, or rather a type of line on an address label. The sort of components we’d typically use for UK addresses are listed in the following table:
| Address Component Type |
|---|
| Addressee |
| Area |
| Building Name |
| Building Number |
| Country |
| County |
| Department Name |
| Dependent Locality |
| Dependent Thoroughfare Name |
| Double Dependent Locality |
| International Post Code |
| Level |
| Locality |
| Mailsort SSC |
| Organization Name |
| PAO End Number |
| PAO End Suffix |
| PAO Start Number |
| PAO Start Suffix |
| PAO Text |
| PO Box |
| Post Code |
| Post Town |
| Postcode |
| Postcode Type |
| SAO End Number |
| SAO End Suffix |
| SAO Start Number |
| SAO Start Suffix |
| SAO Text |
| Street |
| Street Description |
| Sub-Building Name |
| Thoroughfare Name |
| Town |
You could have three or four address lines, plus the post town and postcode. However, the difficulty you will encounter is identifying what these lines actually contain when it matters – e.g. when mapping data between systems. When you carry out data profiling, you will find that Address Line 3 sometimes contains a dependent locality, but at other times it contains a county or locality. Now you’re into natural language processing (NLP); you have to recognize the difference between locality and county. And the permutations multiply as you add more countries.
So we must define all the address components for all the countries we operate in.
Address Formats
Address formats are made up of two parts: a header and its detail. The header is basically the name or title that the address format is known by. Examples could include:
| Address Format Type |
|---|
| Generic 3-line |
| Generic 5-line |
| British Forces Post Office (BFPO) |
| International |
| Post Office Address (PAF) |
| U.S. Address |
| French Address |
Taking the UK’s Full Post Office Address Format (PAF) by way of example, we then define the following address format components:
| Format | Component | Sequence | Is Mandatory? |
|---|---|---|---|
| PAF | Addressee | 1 | N |
| PAF | Organization Name | 2 | N |
| PAF | Department Name | 3 | N |
| PAF | PO Box | 4 | N |
| PAF | Building Name | 5 | N |
| PAF | Sub-Building Name | 6 | N |
| PAF | Building Number | 7 | N |
| PAF | Thoroughfare | 8 | N |
| PAF | Street | 9 | N |
| PAF | Double Dependent Locality | 10 | N |
| PAF | Dependent Locality | 11 | N |
| PAF | Post Town | 12 | Y |
| PAF | Postcode | 13 | Y |
Our application reads this metadata and displays the address components in the correct order. When address capture is required, the metadata tells us whether the address component is mandatory or not.
More often, our application requests the postcode from the end user and looks up the corresponding values and populates the address components automatically. Some applications allow the user to edit the address; other [annoying] ones don’t!
It’s not shown in the PDM, but if your organization operates internationally, you can define a many-to-many relationship between address_format_type and country so that the correct address format (based on the user’s country) is presented to the end user (party).
When and only when the contact_point is a postal address contact_point_type, it must have a relationship to an address_format_type. Conversely, it follows that non-postal address types never have a relationship to an address_format_type. Furthermore, the format must remain fixed for the life of the contact_point, otherwise you’ll introduce the possibility of data integrity issues. (For this not to be the case, the target address_format_components must be a subset of the source address_format_components).
The column contact_value has no meaning for a postal address because the values are stored in address_line.line_content. Conversely, contact_value is mandatory for all other contact_point_types. Basically, contact_point.contact_value and address_line.line_content are mutually exclusive.
The Many-To-Many Relationship Between Party and Contact Point
You can think of contact_point (plus address_line) as containing the values and party_contact as defining the usage. This allows a single contact_point to have multiple uses. Our home [postal] address could also be our billing address and delivery address, depending on the context.
So far, the narrative has assumed that a party owns a particular contact_point. But the data model does not impose this ownership rule! It makes no such restriction whatsoever. There’s another possibility that exists with this design: multiple parties for the same contact points.
You need to consider the implications carefully before venturing down this route.
Here’s an example. In the UK, Awarding Organizations (AOs) generally employ teachers as examiners. A teacher has two relationships: one with the school where he or she works, and another with the AO as an examiner. The school will have a bank of contact_points with various phone numbers and possibly one or more postal addresses. These will be things like the school’s main address (postal address), main email (email address), main fax (fax number), and main phone (phone number).
It is entirely feasible that our examiner can use the very same contact_points as his or her school, but he or she will use party_contact to define them as work-related. If the school’s main phone number changes, the teacher’s work number will automatically be updated, which is pretty neat.
If you go down this route, you will need to define at the application level which party or parties are permitted to update contact_points.
A Quick Word On Performance
The yellow metadata tables are going to be constantly used by queries. Consequently, they are likely to remain in memory. On most RDBMSs, you can pin tables into memory to ensure this. In Oracle, I would create these as index-organized tables, which are small and perform well. Do whatever the equivalent is for your RDBMS.
You also want to ensure that party_contact rows are co-located in the same block (or page) using a clustered index on party_id. Do the same with address_line.contact_point_id. This cuts down on the amount of IO.
Another option exists if you want a party to exclusively own a contact_point. You can then can merge contact_point into party_contact to create party_contact_point (still clustered on party_id). This simplifies the model and could aid performance.
Changing Contacts Doesn’t Mean Changing Databases
We live in a time when it can be said that change is the only constant.
That doesn’t mean that each time something changes it has to impact your database. With a bit of thought, we can future-proof our designs – perhaps more than we have done to date. Doing so helps us to respond quickly to the inevitable change.
If you’re embarking on a green-field project, I would recommend using the Party Model (of which Contact Point is a part) for organizations and people. Why not open up the model and tweak it to your needs? Please feel free to grab a copy and make it your own.
But if your database or databases are already determined, the schema I’ve presented here can still be used, in XML form, to define your payload when integrating data between systems.
