

No matter which side of the equation you’re on, sometimes it’s tough to find a qualified person for a specific job. In this post, we look at a data model to help recruiters and HR departments stay organized during the hiring process.
Most of us have been involved in the hiring process – most often as the job applicant. However, we can also find ourselves involved on the hiring side, maybe by testing the applicant’s technical knowledge. The recruiting process takes a certain amount of time, and the group of applicants grows continuously smaller as we get closer to the final decision. The result should be the selection of the best person for the job.
Recruiting in itself is pretty complicated, so we’ll discuss a fairly comprehensive data model to cover all aspects of the process. Sit back in your chair and enjoy today’s article!
How the Recruitment Process Works
Most parts of the recruitment process are common knowledge, but we’ll discuss exactly how it works before we move on to the data model.
-
Detecting a need
This is an absolute must in the recruitment process; there will be no process if the management is not aware of the need to hire a new employee. That need could be the result of starting a new company, growth in an existing company, or the departure of a current employee.
Unless a company has strictly defined positions (e.g. banks), it’s not always easy to determine when to hire a new employee. Talking with employees and seeing a lot of overtime can spur a new hire. Internal or external regulations can also require that certain positions are only given to people with a specific skillset and relevant working experience (e.g. internal reviser).
-
Outlining the position and its required skills
To get an idea of this step, think of a really well-written job description. It contains:
- A list of all tasks related to the job
- Minimum educational and work experience qualifications
- Specific skills essential to job functions
- Additional or preferred skills
- A summary of what the employer expects from the applicant and what the applicant can expect of this job
- A salary range and maybe a benefits package
This information is important to recruiters and applicants alike. There is no point to inviting ten applicants to the selection process if none of them will be satisfied with the financial offer. And the more detailed the job description, the easier it will be to attract qualified applicants.
-
Defining who will manage the process and when each task should happen
The next step is to define specific dates when each part of the process will happen. Also, companies may assign employees to each step. If the company has a Human Resources department, it will probably manage each part of the recruiting process, although other employees may contribute their specific knowledge when required (e.g. if we’re hiring an IT specialist, the manager of the IT department should assess candidates’ technical skills).
If there is no HR department, we can expect that management personnel will be in charge of the process. In small- and medium-sized companies, this is not only needed, it is desired.
-
Posting the job
Now we’re ready to post a job description on our site, on job boards or aggregators, or in a newspaper. The job post should contain the bullet points listed in Step 2. This will help potential candidates decide whether they want to apply for the position. It’s essential to make the job description accurate; we’ve all wasted our time interviewing for a job that didn’t match its description or our expectations.
-
Selecting, testing, and interviewing candidates
After the application period ends, the applicants with the most relevant skillset and experience will be invited to an initial evaluation phase (usually an interview or test). The other applicants will be informed that they have not been selected for the job. A large company should invite a predefined minimum number of candidates to the initial evaluation. This saves time for both the applicants and the company.
Small- and medium-sized companies could decide to continue the process until they find the best fit. In such cases, the application period will remain open until the right candidate is found and all other dates would be defined along the way.
The interview and testing process will vary by company size and organization. In large companies with HR departments, there will likely be a set of tests to check applicants’ job skills. Other tests may measure psychological and personality traits to determine the applicant-job match, applicant-company match, or even the applicant’s sanity. ☺
These tests will usually be divided into several steps, and each step will reduce the number of applicants.
-
The final interview
This step will probably be an interview of the top few applicants. Small- and medium-sized companies use Interview Management Software to streamline the recruitment process. It is the most important step in the process because the applicants can speak for themselves, demonstrate their competence and personality, and determine if the company and position will be a good fit for them. After this step, the best applicant will receive an offer. If they accept, the recruitment process for that position is over. If the applicant refuses the job offer, the company will make an offer to their next choice.
-
Are there differences in the recruitment process for small, medium, and large businesses? How will we solve them in our model?
There will be certain differences in the recruitment processes of small, medium, and large companies. Plus, the process will vary by the positions being recruited. Think how different the required skills and experiences are for a content manager, an ornithologist, and a cruise ship captain. Some jobs will have more tests and interviews, others may only have a few. But in the end, it all comes down to getting the right answers and to ranking applicants.
In this model, I’ll treat all tests and interviews in the same way. We’ll store each applicant's answers, relate them with the relevant question, and store the applicant’s score for each step of the process.
-
Who can use this data model?
This model is very specific and should only be used for the recruitment process. But it’s not limited to HR departments; you could also use this model to run a professional recruitment service.
-
The Data Model
The data model consists of five main subject areas:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
I’ll describe each subject area separately, in the same order they are listed.
Section 1: Jobs
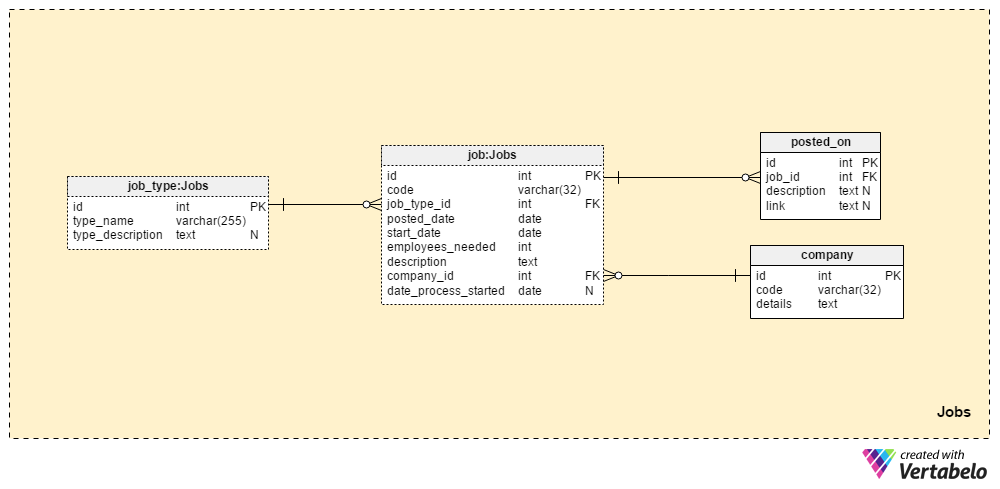
The Jobs section will store all details for all the positions we have ever posted. The two dictionary tables, the company table and the job_type table, are part of the initial setup. The remaining two tables, job and posted_on, contain “real” data related with job postings.
The job_type dictionary contains a list of different and UNIQUE job types. We can expect values like “senior database administrator” or “IT journalist” to be stored in the type_name attribute. The type_description attribute can store a more detailed description of the job.
The company dictionary contains a list of all the companies we work with. If we hire employees only for our company, this dictionary will hold only our company name. If we’re a recruitment agency, it will store the names of every company that hired us.
A list of every job position we have ever posted is stored in the “job” table. The attributes in this table are:
code– Our internal UNIQUE ID used to denote a job.job_type_id– References the related job type.posted_date– The date when this job position was posted.start_date– The expected start date (first working day) for that job.employees_needed– The number of employees we want to hire during this recruitment process. Mostly this will have a value of “1”, but in some cases – e.g. when starting a new company or establishing a new department – we can expect larger values.description– A detailed description of that position. This is the place where we’ll list all required, preferred, and desired job skills.company_id– References the ID of the company that hired us. If we are a recruitment agency, this will refer to a business name stored in thecompanytable. Otherwise, it will be our own company’s ID.date_process_started– The start date of the recruitment process. This could be NULL if we need to define future steps and actions regarding this job.
The last table in this subject area is the posted_on table. For each job_id, we’ll store a link to the job post and the related description. We could use this data to learn where the applicants find our job posts.
Section 2: Applicants, Recruiters and Documents
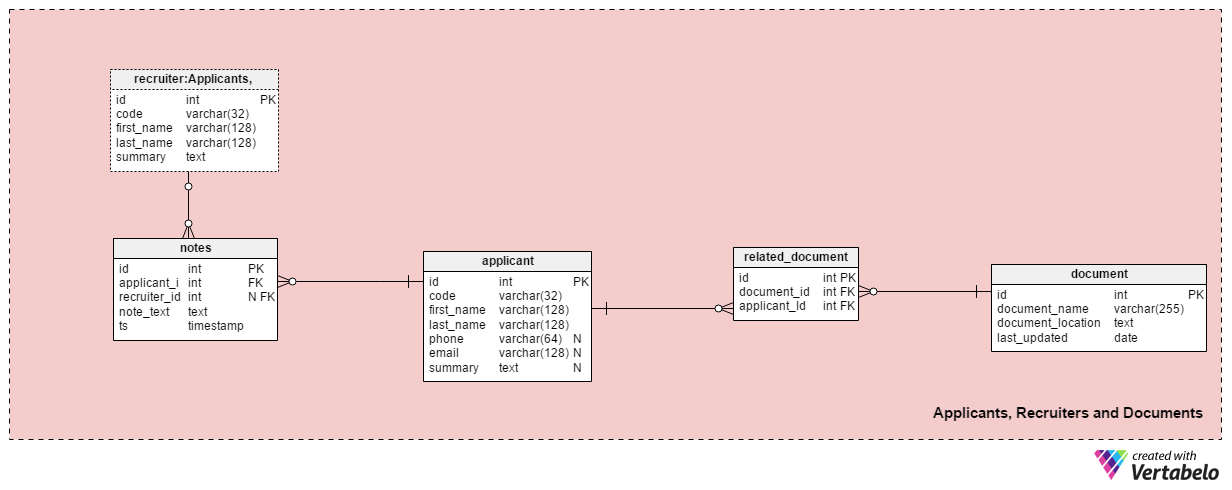
This subject area contains all the tables needed to store information about recruiters, applicants, and their related documents.
The applicant table lists all the applicants we have ever had contact with. Each applicant is UNIQUELY defined in our system with a “code”. Besides that, we’ll store each applicant’s first and last name, phone number, email address, and their summary. This table can be adjusted for specific needs, e.g. adding additional phone numbers, emails, or physical addresses.
We’ll relate applicants with available documents. A list of all available documents (CV or resume, degrees or diplomas, transcripts, certifications, etc.) is stored in the document table. For each document, we’ll store its name in the system, its location, and the time of the most recent update.
We’ll relate applicants with documents using the related_document table. It holds only two foreign keys, which form the document_id – applicant_id UNIQUE pair.
The recruiter table lists the employees who could be assigned to a job application or who enter notes related to an applicant. Each recruiter is UNIQUELY defined by her or his code. We’ll store only basic details like first_name, last_name and the recruiter’s summary.
The last table in this subject area is the notes table. This is where we’ll store all notes related to an applicant. We could store notes like “Applicant missed the meeting” or “Applicant did great on first interview”. For each note, we’ll store the ID of the recruiter who made that note, the ID of the related applicant, the note_text, and the timestamp when the note was created.
Section 3: Test Details
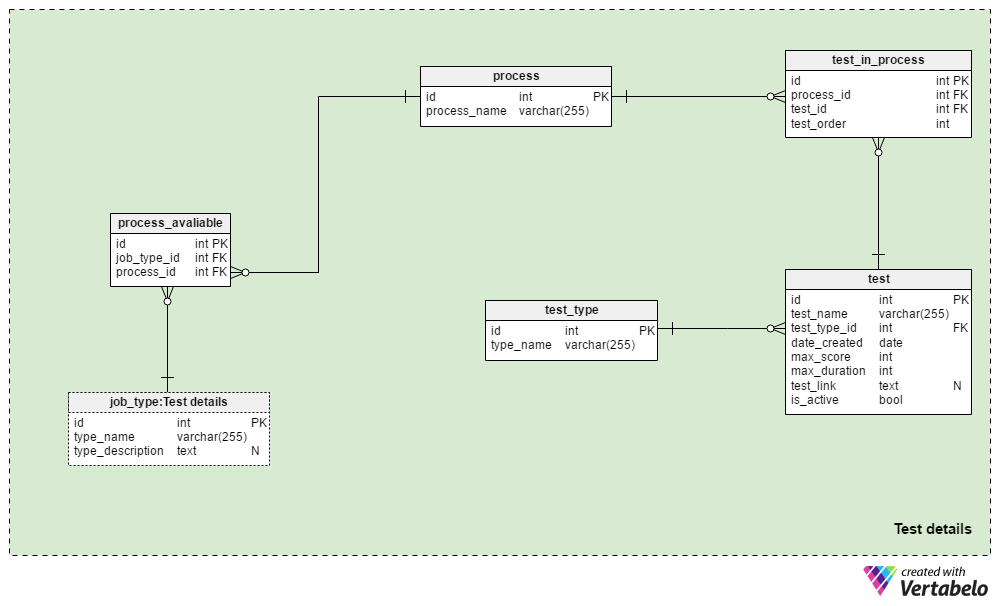
The Test details subject area contains the tables used to define recruitment processes and the tests used during these processes. We’ll generally always use the same selection process for the same job type: changes are only made when they are required by business circumstances. We could use a few different processes for each job type, and we’ll almost certainly use the same process for different job types.
The process table is a simple dictionary containing only a UNIQUE process_name attribute. It lists all the recruiting processes we have ever used and are currently using.
We’ll relate processes with different job types. We’ll store these relations in the process_available table. Its only attributes are the UNIQUE pair job_type_id – process_id. When there are multiple processes available for a job type, this allows the recruiter to choose one.
The test_in_process table is used to define the order of tests during that process. The attributes in this table are:
process_idandtest_id– References the related process and test.test_order– The ordinal number of that test or step in the process. Together withprocess_id, this forms the UNIQUE key of the table. We can have only one step at a time during the process.
The test table lists all tests currently and previously used in the recruitment process. We’ll also treat CV reviews and interviews as tests. Although they don’t need questions and answers defined, they are part of an evaluation. For each test, we’ll store:
test_name– A UNIQUE designation for each test.test_type_id– References thetest_typedictionary.date_created– The date when we created this test in our system.max_score– The max score achievable for this test. This value is the sum of all correct answers on this test or the highest grade that recruiters could give to a CV or interview.max_duration– How long (in minutes) the applicant has to complete the test.test_link– Contains a link to the test location. This value could be NULL when we don’t use a test in the process.is_active– Denotes if we currently use this test.
We’ve already mentioned the test_type dictionary. It contains all the UNIQUE test names by format, e.g. “CV review”, “online skill test”, "paper skill test” and “interview”.
This model doesn’t include the structure needed to store test questions and answers. Rather, it stores a link to the locations that contain this information. The same design will be used in the Applications subject area.
Section 4: Applications
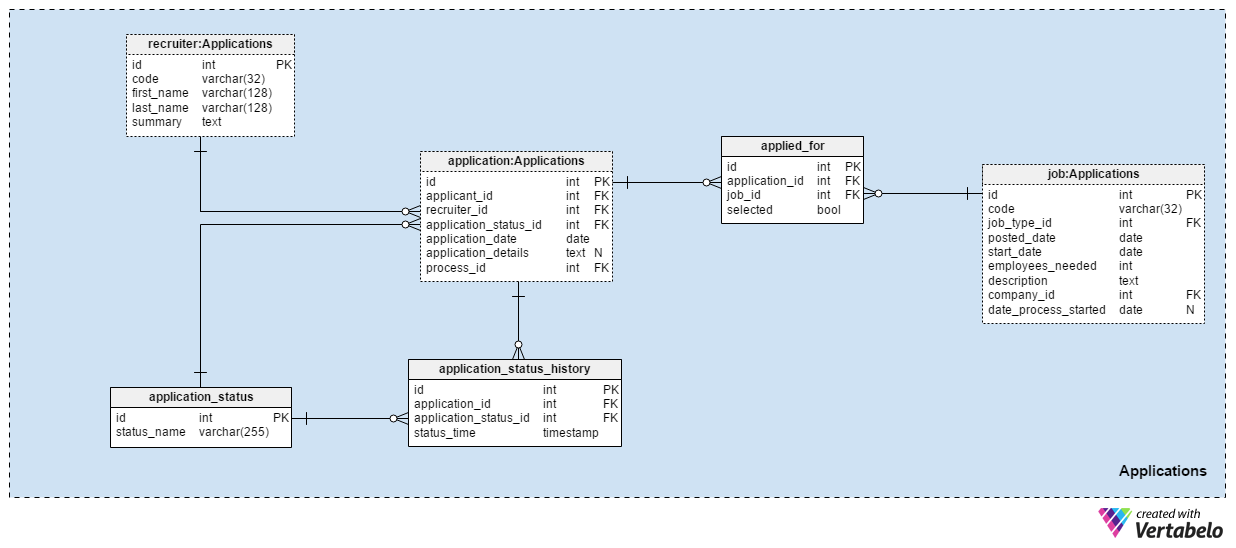
The Applications subject area is the probably the most important in this data model. All other subject areas mentioned so far described applications. This one stores the real things.
Every application we’ve ever received is recorded in the application table. For each application, we’ll store the related applicants’ ID, the recruiters’ ID, and a reference to the current status of that application. We’ll update this status at the same time we make a new entry in the application_status_history table. The application_date attribute is used to store the relevant date, while all additional details are stored in text format. The process_id attribute stores a reference to the process selected for that application.
Applications will change status over time. A list of all application statuses is stored in the application_status dictionary. The only attribute is status_name and it can only hold UNIQUE values. Expected values include: "applied", "CV reviewed", "chosen for the test", "rejected after CV review", "passed the test", "invited to an interview" and "terminated by applicant".
We’ll store all application statuses in the application_status_history table. This table contains references to the application table and the application_status dictionary. We’ll also store the exact status_time when this status was assigned to the application. The application_id – status_time pair forms the UNIQUE key of this table.
In most cases, an applicant will apply for only one position with one application. It is possible that an applicant will apply for more than one position and we’ll choose the most suitable role for them during the selection process. In the applied_for table, we’ll store the UNIQUE pair application_id – job_id. We’ll also record whether the applicant related with that application was selected for that position. We can expect that all selected values will be set to “False” at the beginning of the selection process and that we’ll update only one per each job position to “True”.
Section 5: Application Tests
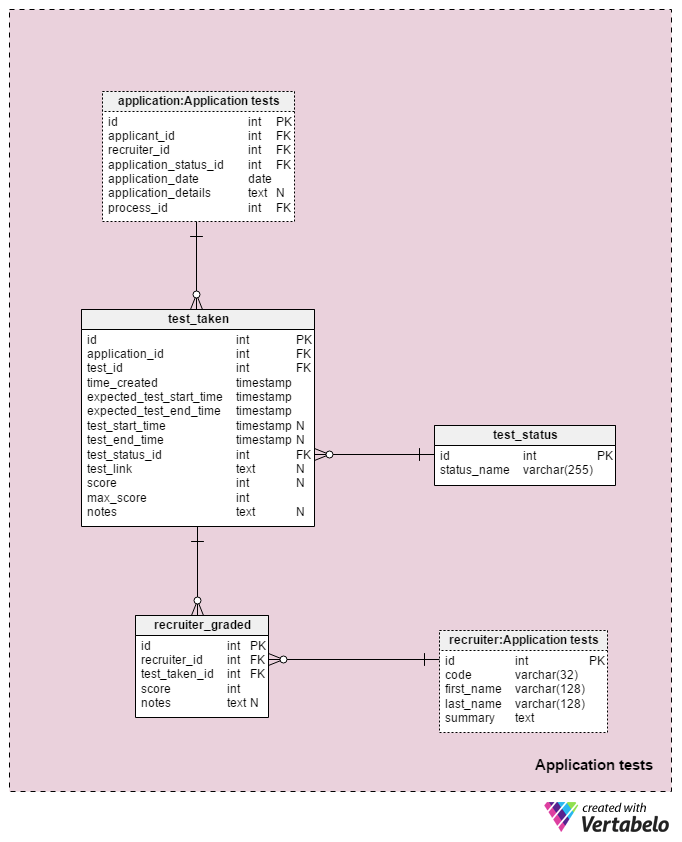
The last subject area in our model will be used to store the results of every test taken during the selection process. Two tables used in this subject area are copies from other subject areas: application and recruiter. They are used here to simplify the model.
All details related with each test are stored in the test_taken table. This table also holds all other steps in the process that could be graded, like a CV review. The attributes in this table are:
application_id– References theapplicationtable. This relates a test with the applicant who took that test.test_id– References thetestcatalog. We could also reference thetest_in_processtable here, which would provide us with more information about the test taken. I decided not to because this structure provides us with more flexibility. (E.g. if we want to allow applicants to take a test twice or outside usual times).time_created– The actual time we inserted this test into our system.expected_test_start_timeandexpected_test_end_time– The start and end times, as discussed with the applicant. We could change these values in case the applicant or the recruiter needs to postpone the test.test_start_timeandtest_end_time–The actual start and end times for the test. These will contain NULL values when the test is created; values will be updated when the applicant starts and ends this test.test_status_id– References thetest_statusdictionary.test_link– Links to the test with the applicant’s answers. It will be updated when the applicant submits the test.score– The applicant’s score on that test. This is either determined manually by a recruiter (e.g. for a CV review) or automatically (the sum of all test item scores). It could also hold a NULL value for tests that are not scored or graded on some predefined scale. Plus, a test that is scheduled but not yet completed can have a NULL value.max_score– The test’s maximum achievable score. This is the same as the value stored in thetest.”max_scoreattribute. I want to keep that value because the recruiter could modify the test while it’s being given and therefore change the maximum score that could be achieved.notes– Any additional notes or remarks entered by recruiters regarding that specific test.
The combination of the test_id – application_id – expected_test_start_time attributes forms the UNIQUE key of this table. Before adding a new test session, we should still check for overlapping test intervals for the related applicant and all related recruiters.
The test_status dictionary contains a list of every UNIQUE status_name that could be assigned to a test. Some expected values include: "not started", "in progress", "completed successfully", "completed unsuccessfully", "postponed", "canceled" and "applicant canceled".
The last table in our model is the recruiter_graded table, which stores all grades recruiters gave when grading each test. Therefore, we’ll store references to the recruiter and test_taken tables. We’ll also store the score achieved as well as any notes. This information is very important, especially when we’re grading tests manually (i.e. for CV reviews and interviews).
Today we’ve discussed a data model that can cover nearly any situation in the selection and recruitment process – including uncommon exceptions.
Most of us have some expertise with this topic. Please share your experience while you were in the role of the recruiter or on the other side of the desk. Does this model cover the situations you faced? If not, what changes would you propose?
