

Designing a clear physical data model can be challenging – especially when you don’t stop to consider these eight critical areas. Get our expert tips on creating a better physical model.
A physical model is the technical implementation of a logical data model. It has a higher level of detail and is specifically created for a particular database vendor, taking into account that database management system’s technical features and restrictions. Creating a physical data model allows us to implement a database design made for a specific database vendor.
Before we get into the details of creating a physical data model, you may want to read the articles What Are Conceptual, Logical, and Physical Data Models? and How to Implement a Conceptual, Logical, and Physical Data Model in Vertabelo to fully understand the differences between them and how to start creating data models using the Vertabelo database modeler.
When Do We Need a Physical Model?
We need a physical model when:
- We have completed a database design at a logical level, and
- We want to implement it “physically”, i.e. by creating a database to start using the software we are building.
The database modeling process usually implies starting with a high-level (i.e. conceptual) model and then evolving it into a logical model, where the entities (including the attributes) and the relationships between them are described from a business perspective, without considering technical aspects.
A physical model is the evolution of the logical model, where we must consider all technical restrictions in the target database engine as well as include the features and enhancements that it provides. At this point, we must also consider our organization’s naming conventions and guidelines, ensuring the database being created complies with them.
In some software projects, we may be able to decide the target database management system (DBMS)first, thus benefiting from specific features that would adapt better to the software being developed. In most situations, we may be forced to use a specific database engine (based on the customer’s requirements, price limitations, etc.). Having a solid logical model and using a design tool like Vertabelo will help us evolve that model into the physical data model with less effort.
8 Technical Considerations for a Physical Data Model
Before starting a physical model, we need to know the target database engine. This makes it easier to design a physical model that can be implemented without errors.
To help you understand these technical considerations and where to find them in Vertabelo, we’ll use a very simple physical diagram as an example, with SQL Server as the target DBMS. Here’s the schema:
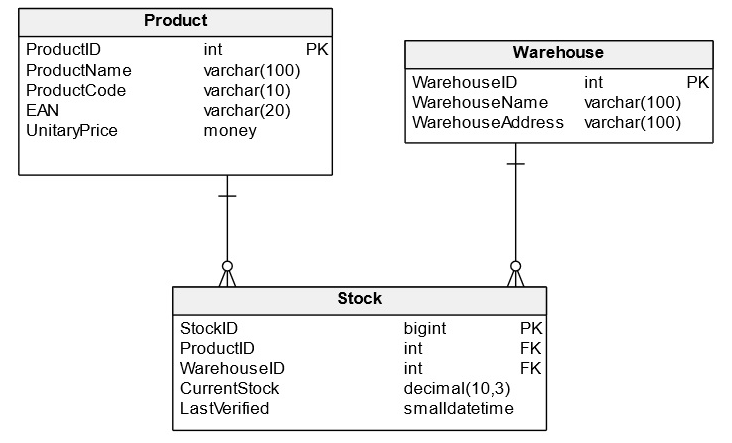
Now let’s review the most common technical considerations included in most physical models.
1. Object Name Length
Different database engines have different limits on object names.
For example, up to Oracle 12.1, tables, columns, constraints, and all other object names were limited to 30 characters; Oracle 12.2 allows names to be up to 128 bytes for all objects except tablespaces (which are still limited to 30 characters). Database names are still limited to 8 characters. There is a feature in Vertabelo that validates all of these conditions for you; learn more about it in the article “How Model Validation Works in Vertabelo”.
As a rule, avoid using very long names. Also, avoid using too many abbreviations; this can make it impossible to understand the table contents, the column or constraint meanings, etc.
2. Data Types
Each database engine supports different data types. Defining the correct type for each column (attribute) requires knowing both the business requirements and the data types available in the target database engine.
For example, SQL Server includes the TINYINT, SMALLINT, INT, and BIGINT data types for integer values; they require 1, 2, 4 and 8 bytes of storage respectively. Choosing a data type that’s too small for a particular column may require changing it in the future (which can be a resource-intensive task, expensive both in money and time). Choosing a data type that’s too big can produce performance degradation and excessive resource consumption. For example, using a BIGINT to store numbers from 1 to 100 would require 8 bytes of storage per number instead of 1; each index search would have to compare 8 bytes instead of 1 byte.
You should plan ahead and figure out the appropriate data type, size, and precision for each attribute. Consider future usage, but avoid oversizing.
3. Constraints
Most database engines allow the creation of constraints to enforce rules. Those constraints include the:
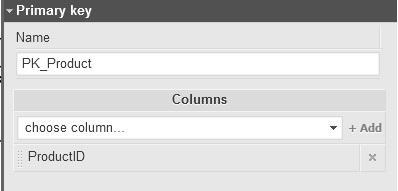
- Primary Key: A column or set of columns that uniquely identify each row in a table; a table can have one and only one primary key. Primary keys cannot accept NULLs. Most modern designs use surrogate keys (i.e. auto-generated values like identity columns) rather than natural keys as primary k For a great explanation on the pros and cons of both approaches, see Designing a Database: Should a Primary Key Be Natural or Surrogate?.
- Unique Key(s): A column or set of columns that are unique in a table. A table may have many unique keys. For example, the Product table may have a unique key on the ProductCode column that’s defined by the business (meaning that it does not allow two products to have the same code) and another unique key on the
EANcolumn. (An EAN or IAN is a standard product identification code that’s used in 100+ countries.)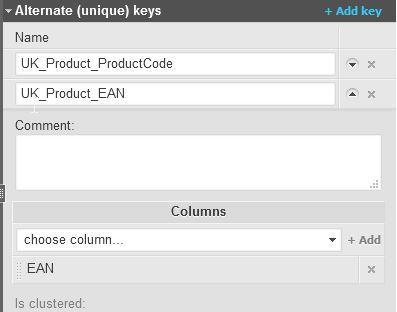
- Foreign Key: Enforces that a value stored in a column or set of columns must exist and be unique on another table. For example, the foreign key on the
ProductIDcolumn of ourStocktable points to a record in theProducttable and indicates that:- The value stored in the
ProductIDcolumn must exist in theIDcolumn of theProducttable. - This value must be unique. Foreign keys must point to a primary or unique key in the referenced table.
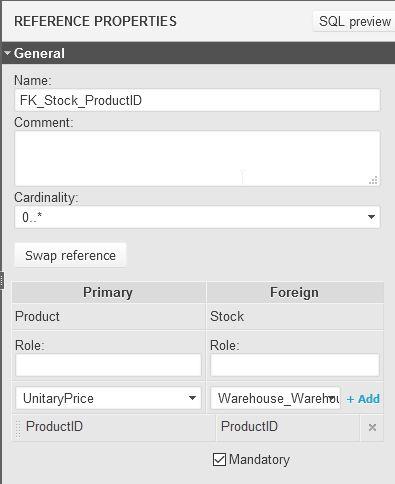
- The value stored in the
- Not Null: This constraint ensures a valid value is stored in the column; the column cannot be left blank. In Vertabelo, all columns are not nullable by default; you have to explicitly allow them to accept nulls by checking the box, as shown below.
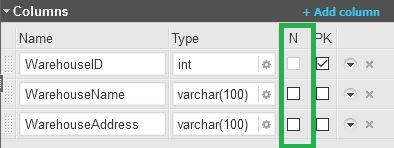
- Check Constraint: A check constraint ensures that a column or set of columns obey a custom rule. For example, the
Stocktable may have a check constraint with the condition “CurrentStock >= 0”, meaning that the system will not allow negative values in that column.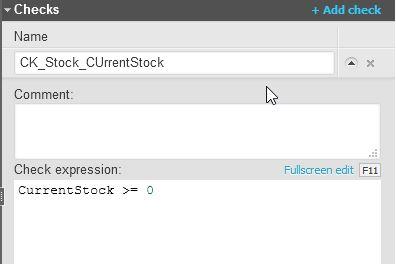
4. Defaults
Default values are a useful feature, providing a default value for a column when its value is not specified when its record is inserted/created. For example, the LastVerified column could have a DEFAULT set to GETDATE(), meaning that the column should use the current date if no value is specified during record creation.
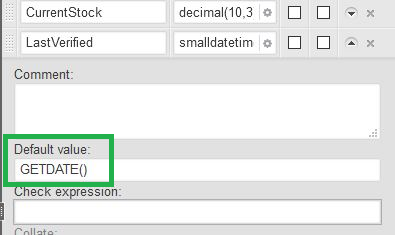
5. Indexes
Indexes can be placed on one or more columns to speed up access to information. Most data models initially include some indexes. More indexes may be added once the system is in use (based on performance suggestions from database administrators).

6. Storage and Partitioning
Tables and indexes store information, which means that you need to define where to physically place that data on a disk. Database engines include logical options (e.g. tablespaces in Oracle or filegroups in SQL Server) that allow users to define a logical unit where the table(s) will reside (keeping them independent of the actual physical location). Then those logical units are assigned files (i.e. datafiles in Oracle, files in SQL Server) that are the actual place where the data will be stored in the filesystem.
Additionally, tables and indexes can be partitioned. This means that a table will be stored in different physical places while still being accessed as a single unit. Partitioning is a key way to enhance access performance. For example, you can partition an Invoice table using the Invoice Date as the partition key and defining that:
- The current year’s invoices are stored on a very fast disk (which is expensive).
- Invoices for the last two years are stored on a normal disk.
- Invoices over three years old are stored on a slower (but cheaper) set of disks.
This allows us to very quickly access current information, while not spending so much money on older (and rarely used) data.
7. Security
Most database engines allow for encryption at rest (meaning that the data is automatically encrypted before it is written to disk and decrypted when it is read from disk). Additionally, some tables that hold sensitive information, like social security numbers or salaries, may require additional security considerations. One example is column encryption, which means that the content of the column is encrypted once it is read from disk; only some users can decrypt it and access the values stored.
8. Triggers, Views, Procedures and Functions
Database engines include some additional objects that are usually considered as code:
- Views simplify querying the database; a view is a simple object that can internally reference many tables with complex join and filter conditions, groupings, etc.
- Triggers are small pieces of code written in proprietary programming languages (PL/SQL in Oracle or T-SQL in SQL Server) that execute automatically whenever a row is inserted, deleted or updated in a table.
- Procedures and functions are pieces of code (written in proprietary programming languages) that are stored in the database, as they are used regularly directly on the database.
These objects can also be defined and included in a physical data model.
Organization Considerations
Besides the technical restrictions and features that depend on the technology being used, there are other things to consider when creating a physical data model. Those are the standards or definitions set by the organization that owns the software we are developing.
Each organization may have plenty of conventions and rules that must be followed. I’m just going to mention a couple of the most common examples.
1. Object Naming Conventions
Many organizations have their own naming conventions. These ensure that names used in different software pieces follow a standard definition, making the names easier to understand. Such conventions may include:
- Using specific prefixes for objects:
- Using a “t” or a “v” before a table name or view name, respectively.
- Using “fk”, “pk”, or “uk” before a foreign key, a primary key or a unique k
- Using “ix” before index names.
- Complex names, separators, and naming cases:
- Use “_” to separate words in a complex name enhances readability (especially when the database engine stores names in uppercase, as Oracle does). Example:
DATE_OF_BIRTHinstead ofDATEOFBIRTH - Use PascalCase or camelCase to separate words (when the database engine stores names maintaining the case used on creation, as SQL Server does). Example:
DateOfBirthordateOfBirthinstead ofdateofbirth.
- Use “_” to separate words in a complex name enhances readability (especially when the database engine stores names in uppercase, as Oracle does). Example:
Check the Stock diagram example and try to identify the naming conventions used. There is no perfect naming convention, but even the worst naming convention is better than no convention at all!
2. Data Types
Some organizations may decide to use specific data types to keep commonality between systems. For example, they may decide to use the TIMESTAMP datatype in Oracle ( which allows the storage of milliseconds) for dates that do not require that precision (like an invoice date) to make the interaction between different systems simpler.
Creating a Physical Data Model in Vertabelo
Using Vertabelo, you can easily create a physical diagram using a previously-defined logical diagram, as explained in the article How to Generate a Physical Diagram from a Logical Diagram in Vertabelo. You can also create a physical data model from scratch – although having a logical model first is usually the right way to go! This is explained in How to Create Physical Diagrams in Vertabelo.
What’s Next?
We have just reviewed when a physical data model is needed and what considerations (both technical and organizational) we must consider when creating one. We also took a quick look at how to use the Vertabelo Database Modeler to create a physical model, either from scratch or based on an existing logical model.
Now it’s your turn! Use the Comments section to share your thoughts on this article, ask any additional questions, or discuss your database model doubts.
