

In this era of tough competition, job portals are not just platforms for publishing and finding jobs. They are leveraging advanced services and features to keep their customers engaged. Let’s dive into some advanced features and build a data model that can handle them.
I explained the basic features needed for a job portal website in a previous article. The model is shown below. We’ll consider this model as a base, which we will change to meet the new requirements. First, let’s consider what these requirements (or enhancements) should be.
What Are We Adding to the Online Job Portal Data Model?
Briefly, we’re going to add four enhancements to our former data model:
- A Personal Dashboard for Job Seekers. This keeps track of all their job applications and provides real time updates on any status changes (i.e. an application changes from being received to being reviewed).
- A Profile Dashboard. This details who is visiting a job seeker’s profile and how many times their resume was downloaded in the last day, week, or month.
- Paid Service Management. Job portals often offer services like expert resume preparation, social profile management, career consulting, etc. Our new functionalities will be able to support for-pay offerings.
- Pre-Application Form Management. As applicants submit a job application, they may be asked to fill out a short questionnaire related to work times, locations, and background checks. We will build in ways for this form to be customized by recruiters and for questions and responses to be captured by the system.
Enhancement# 1: Personal Dashboard
Questions to Answer: What is the current status of a submitted application? Is it shortlisted for an interview? Has it even been viewed yet?
We can keep track of job applications by putting the job_application_status_id column in the job_post_activity table. This column holds the current status of a job application. We need to create another table, job_application_status, to hold all possible application statuses. Some statuses might be ‘submitted’, ‘under review’, ‘archived’, ‘rejected’, ‘shortlisted for interview’, ‘under recruitment process’, and so on.

Another new table, job_post_activity_log, stores information regarding all actions performed on job applications, who performed the action, and when it was performed. This table contains the following columns:
id– The primary key of the table.job_post_activity_id– The application ID on which the action is performed.job_post_action_id– The ID of the action performed. This is a foreign key that links to thejob_post_actiontable. The types of actions we might store here include ‘submitted’, ‘viewed’, ’interviewed’, ’written test taken’, ‘offer in process’, ’offer dispatched’, ‘offer accepted’, etc.action_date– The date when an action was performed.user_account_id– The ID of the person who performed the action.
Is “job_post_action” identical to “job_application_status”? How are they different?
They seem identical at first, but they are indeed different. There are valid reasons why we need two similar fields:
- A candidate is interviewed by two or more people separately. In this case, the job application status remains the same (i.e. ‘undergoing recruitment process’) until all interview rounds are complete. However, records for each individual interviewer are inserted into the
job_post_activity_logtable, and they have the action ‘interviewed’. - An application can be viewed by more than one recruiter in the same company. By using these two attributes, you won’t lose an applicant’s information.
- Making an offer to a selected candidate is subject to multiple approvals (i.e. approval from finance team, approval from the hiring department manager, and so on). In this case, a job application’s status remains ‘offer under review’, but the database can log which approvals have come through and which have not by means of the
job_post_activity_logtable.
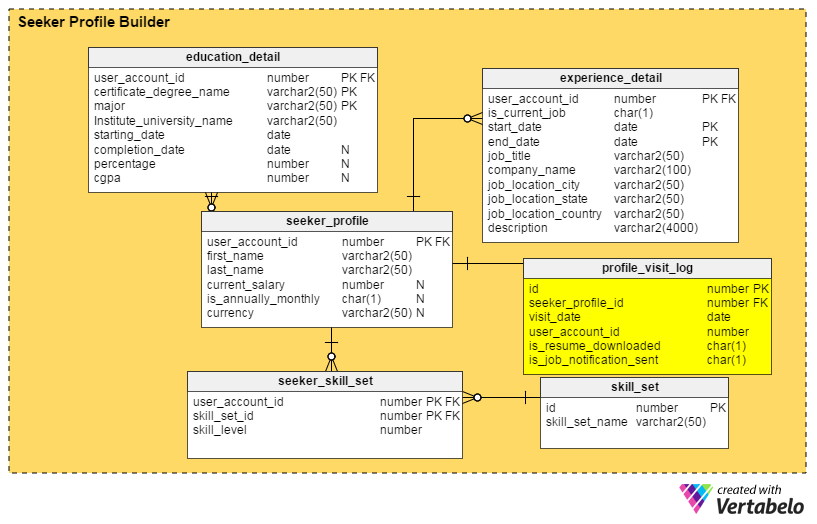
Enhancement# 2: A Profile Dashboard
Questions to Answer: Who has found my profile recently? How many times was it viewed by recruiters in the last month, week, or day? Did recruiters from top companies look at my profile?
The answers to all of these questions are in the profile_visit_log table. This table captures all profile visit data, including who visited a profile, when it was viewed, and so on. The columns in this table are:
id– The primary key of the table.seeker_profile_id– Which profile was visited.visit_date– When the profile was accessed.user_account_id– Who saw the profile.is_resume_downloaded– A flag column that denotes if the related resume was downloaded during the visit. This column will help us derive how many times a resume is downloaded by recruiters.is_job_notification_sent– Another flag column, this one stating whether a job notification was sent to the profile’s owner.
Enhancement# 3: Paid Service Management
Question to Answer: How can online portals leverage additional for-pay services?
Besides a platform for posting and searching jobs, many online portals provide other services, like expert resume building, career consulting, etc. They also offer products to help job seekers find their dream job in their dream city. For example, one of the leading job sites offers a product that keeps your profile on the top of recruiters’ lists so you can get more interview offers. Most of these products or services are available on a subscription basis. When a user purchases a service or product, they pay over a specific time period (i.e. a month, three months, one year) for usage of that product or service.
As I looked at these job portals, I noticed that hardly any products or services are offered singly. For the most part, multiple products and services are bundled together into a package, and this package is offered to either job seekers or recruiters.
Taking into account all these points, I came up with the following data model for incorporating paid services and products into our existing online job site:
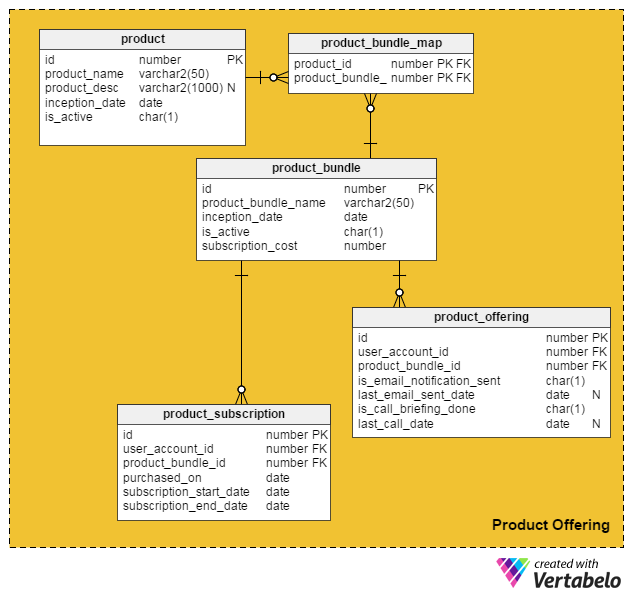
The product table holds details about individual products. (We’ll refer to both products and services as “products”). The columns in this table are:
id– The primary key of this table, which gives a unique ID to each product offered on our portal.product_name– Holds the product’s name.product_desc– Stores a brief description of the product.inception_date– The date when a product was introduced.is_active– Whether a product is active or not.
Since products and services can be clubbed together in a bundle and offered to customers, I created the product_bundle table to store records of all such bundles. The attributes are:
id– The primary key of the table, which provides a unique ID for each product bundle.product_bundle_name– Stores the bundle’s name.inception_date– The date when the bundle was introduced.is_active– Denotes whether a bundle is active or not.subscription_cost– Stores the price asked for the bundle.
Can a single product be offered to customers?
Yes. In this data model, a single product can be its own “bundle”. The following tables handle this and some other important functionalities.
The product_bundle_map table stores a list of all products that are part of a bundle. Its attributes are self-explanatory.
The next table, product_subscription, comes into play when customers subscribe to product bundles. It records the details of which customers have scribed to which bundles. The columns in this table are:
id– The primary key of the table.user_account_id– The user who purchased the bundle.product_bundle_id– The product bundle bought by the user.purchased_on– The date of purchase.subscription_start_date– The date when the subscription starts. Note that the product purchase date and the subscription start date may differ. Thus, we have two different columns for these.subscription_end_date– When the subscription will end.
The final table, product_offering, is mainly used for marketing. Usually job portals analyze users’ recent activities (both job seekers and recruiters) and then decide which products will be beneficial to which users. They then use emails or phone calls to contact customers with selected offerings. The columns for this table are:
id– The primary key of the table.user_account_id– The user whom the job portal is targeting.product_bundle_id– The product bundle that the portal marketers have matched to the user.is_email_notification_sent– Whether an email regarding the product offering has been sent.last_email_sent_date– When the user last received a product email from the marketing team. It’s common for marketers to send multiple notifications to a user, and to send other notifications periodically. This column stores the date when the last notification was sent.is_call_briefing_done– Whether the customer received a phone call briefing them about a product.last_call_date–The date of the most recent telephone call. There can be multiple calls (follow-up calls) made to customers.
Enhancement# 4: Pre-Application Form Management
Question to Answer: How can a recruiter get a customized consent form filled by all potential job candidates?
Many times, job seekers to answer specific questions as they apply for a post. This commonly includes things like consenting to a criminal background check. However, there are various other types of consents that may be needed. For example, a job in marketing may require lots of travel; jobs in business process outsourcing (BPO) may require employees to work graveyard (i.e. late-night) shifts. These are addressed in pre-application forms.
It is always best to get consent when the job application is submitted. This way, candidates unwilling to meet these requirements won’t apply to the job.
Before jumping to the data model, let me first highlight some basic facts about consent forms:
- A job post can have more than one consent form.
- Each consent form has various questions associated with various sections.
- A question can be set as mandatory or optional, depending on how the question is tagged in the form. A question can be optional in one form and mandatory in another.
- Each question can be answered as either (1) yes, (2) no, or (3) not applicable.
- All answers will be recorded.
I’ve used the following four tables to manage questions and consent forms. The first, the question table, holds a list of questions. It has these attributes:
id– The primary key of the table, which gives a unique ID number to each question.question_text– Stores the actual question text.question_section_id– The section where the question appears. (E.g. “Have you worked in software development for at least five years?” would appear in the “Work Experience” section.) This is a foreign key column that is referred from thequestion_sectiontable.
The question_section table stores section information. It is a way to group questions related to the same topic. Aside from the id attribute, which is the primary key for the table, the only attribute is section_name, which is self-explanatory.
The consent_questionnaire table holds consent form names. Its two attributes are also self-explanatory.
The ques_consent_questionnaire_map table is the core of this subject area. All other tables in this subject area are directly or indirectly connected with it. Its purpose is to keep a list of questions tagged to consent forms. The columns in this table are:
id– The primary key of this table.consent_questionnaire_id– The consent form’s ID number.question_id– The question’s ID number.is_mandatory_optional– Signifies whether the question is mandatory or optional for a given consent form. A question can be part of multiple consent forms, but it can be mandatory in some and optional in others. That is the sole reason behind keeping this column here instead of having it in thequestiontable.
The next few tables we’ll discuss tag consent forms to individual job posts and record candidates’ answers. Let’s start with the job_post_questionnaire table, which stores information about what consent forms are part of a job post. There can be one or more consent forms tagged with a job post. The columns in this table are:
id– The table’s primary key.job_post_id– Denotes which job post the consent form is tagged with.consent_questionnaire_id– The consent form tagged to a job post.
Next, the appl_questionnaire_answer table logs the individual answers of each consent form question as filled by the applicants. The columns in this table are:
job_post_activity_id– A foreign key column referred from thejob_post_activitytable. It stores information about the candidate who has answered the question.quest_consent_quesnnaire_map_id– Another foreign key column referred from thequest_consent_questionnaire_maptable. It stores which question from which consent form is being answered.answer– The job applicant’s actual answer. I have kept it as a CHAR(1) column because all questions in our model can be answered as ‘Yes’ (answer = ‘Y’), ‘No’ (answer = ‘N’) or ‘Not Applicable’ (answer = ‘X’).
The New and Improved Online Job Portal Data Model
You can see the completed data model below.
What Would You Add?
Can you think of any other features to add to our online job portal? Please share your views in the comments section.
