

Having reference tables in your database is no big deal, right? You just need to tie a code or ID with a description for each reference type. But what if you literally have dozens and dozens of reference tables? Is there an alternative to the one-table-per-type approach? Read on to discover a generic and extensible database design for handling all your reference data.
This unusual-looking diagram is a bird’s-eye view of a logical data model (LDM) containing all the reference types for an enterprise system. It’s from an educational institution, but it could apply to the data model of any kind of organization. The bigger the model, the more reference types you’re likely to uncover.
By reference types I mean reference data, or lookup values, or – if you want to be flash – taxonomies. Typically, the values defined here are used in drop-down lists in your application’s user interface. They may also appear as headings on a report.
This particular data model had about 100 reference types. Let’s zoom in and look at just two of them.
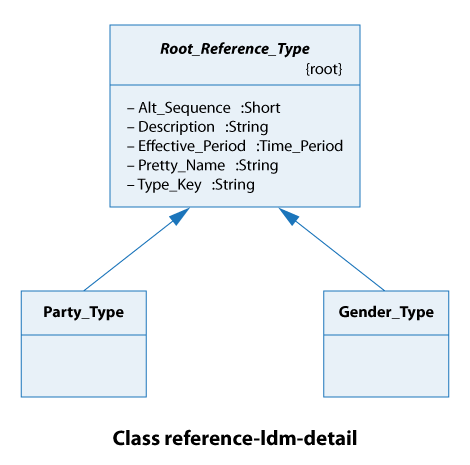
From this class diagram, we see that all reference types extend the Root_Reference_Type. In practice, this just means that all our reference types have the same attributes from Alt_Sequence thru to Type_Key inclusive, as shown below.
| Attribute | Description |
|---|---|
Alt_Sequence | Used to define an alternative sequence when a non-alphabetic order is required. |
Description | The description of the type. |
Effective_Period | Effectively defines whether or not the reference entry is enabled. Once a reference has been used it cannot be deleted due to referential constraints; it can only be disabled. |
| The pretty name for the type. This is what the user sees on screen. |
Type_Key | The unique internal KEY for the type. This is hidden from the user but application developers can make extensive use of this in their SQL. |
The type of party here is either an organization or a person. The types of gender are male and female. So these are really simple cases.
The Traditional Reference Table Solution
So how are we going to implement the logical model in the physical world of an actual database?
We could take the view that each reference type will map to its own table. You might refer to this as the more traditional one-table-per-class solution. It’s simple enough, and would look something like this:
The down-side of this is that there could be dozens and dozens of these tables, all having the same columns, all doing very much the same thing.
Furthermore, we may be creating a lot more development work. If a UI for each type is required for administrators to maintain the values, then the amount of work quickly multiplies. There are no hard and fast rules for this – it really depends on your development environment – so you’ll need to talk to your developers to understand what impact this has.
But given that all our reference types have the same attributes, or columns, is there a more generic way of implementing our logical data model? Yes, there is! And it only requires two tables.
The Two-Table Solution
The first discussion I ever had about this subject was back in the mid-90’s, when I was working for a London Market insurance company. Back then, we went straight to physical design and mostly used natural/business keys, not IDs. Where reference data existed, we decided to keep one table per type that was composed of a unique code (the VARCHAR PK) and a description. In point of fact, there were far fewer reference tables then. More often than not, a restricted set of business codes would be used in a column, possibly with a database check constraint defined; there would be no reference table at all.
But the game has moved on since then. This is what a two-table solution might look like:
As you can see this physical data model is very simple. But it’s quite different from the logical model, and not because something has gone all pear-shaped. It’s because a number of things were done as part of physical design.
The reference_type table represents each individual reference class from the LDM. So if you have 20 reference types in your LDM, you’ll have 20 rows of meta-data in the table. The reference_value table contains the permissible values for all the reference types.
At the time of this project, there were some quite lively discussions between developers. Some favored the two-table solution and others preferred the one-table-per-type method.
There are pros and cons for each solution. As you might guess, the developers were mostly concerned with the amount of work the UI would take. Some thought that knocking together an admin UI for each table would be pretty quick. Others thought that building a single admin UI would be more complex but ultimately pay off.
On this particular project, the two-table solution was favored. Let’s look at it in more detail.
The Extensible and Flexible Reference Data Pattern
As your data model evolves over time and new reference types are required, you don’t need to keep making changes to your database for each new reference type. You just need to define new configuration data. To do this, you add a new row to the reference_type table and add its controlled list of permissible values to the reference_value table.
An important concept contained in this solution is that of defining effective periods of time for certain values. For example, your organization may need to capture a new reference_value of ‘Proof of ID’ that will be acceptable at some future date. It is a simple matter of adding that new reference_value with the effective_period_from date correctly set. This can be done in advance. Until that date arrives, the new entry will not appear in the drop-down list of values that users of your application see. This is because your application only displays values that are current, or enabled.
On the other hand, you may need to stop users from using a particular reference_value. In that case, just update it with the effective_period_to date correctly set. When that day passes, the value will no longer appear in the drop-down list. It becomes disabled from that point on. But because it still physically exists as a row in the table, referential integrity is maintained for those tables where it has already been referenced.
Now that we were working on the two-table solution, it became apparent that some additional columns would be useful on the reference_type table. These mostly centered on UI concerns.
For example, pretty_name on the reference_type table was added for use in the UI. It is helpful for large taxonomies to use a window with a search function. Then pretty_name could be used for the title of the window.
On the other hand, if a drop-down list of values is sufficient, pretty_name could be used for the LOV prompt. In a similar way, description could be used in the UI to populate roll-over help.
Taking a look at the type of config or meta-data that goes into these tables will help clarify things a bit.
How to Manage All That
While the example used here is very simple, the reference values for a large project can quickly become quite complex. So it may be advisable to maintain all of this in a spreadsheet. If so, you can use the spreadsheet itself to generate the SQL using string concatenation. This is pasted into scripts, which are executed against the target databases that support the development life-cycle and the production (live) database. This seeds the database with all the necessary reference data.
Here is the config data for the two LDM types, Gender_Type and Party_Type:
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
There is a row in reference_type for each LDM subtype of Root_Reference_Type. The description in reference_type is taken from the LDM class description. For Gender_Type, this would read “Identifies the gender of a person”. The DML snippets show the differences in descriptions between type and value, which may be used in the UI or in reports.
You will see that reference_type called Gender_Type has been allocated a range of 13000000 to 13999999 for its associated reference_value.ids. In this model, each reference_type is allocated a unique, non-overlapping range of IDs. This is not strictly necessary, but it allows us to group related value IDs together. It kind of mimics what you’d get if you had separate tables. It’s nice to have, but if you don’t think there’s any benefit in this then you can dispense with it.
Another column that was added to the PDM is admin_role. Here’s why.
Who Are The Administrators
Some taxonomies can have values added or removed with little or no impact. This will occur when no programs make use of the values in their logic, or when the type is not interfaced to other systems. In such cases, it is safe for user administrators to keep these up to date.
But in other cases, much more care needs to be exercised. A new reference value may cause unintended consequences to program logic or to downstream systems.
For example, suppose we add the following to the Gender Type taxonomy:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
This quickly becomes a problem if we have the following logic built in somewhere:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Clearly, the “if you’re not male you must be female” logic no longer applies in the extended taxonomy.
This is where the admin_role column comes into play. It was born from discussions with the developers on the physical design, and it worked in conjunction with their UI solution. But if the one-table-per-class solution had been chosen, then reference_type would not have existed. The meta-data it contained would have been hard-coded into the application Gender_Type table – , which is neither flexible nor extensible.
Only users with the correct privilege can administer the taxonomy. This is likely to be based on subject matter expertise (SME). On the other hand, some taxonomies may need to be administered by IT to allow for impact analysis, thorough testing, and for any code changes to be harmoniously released in time for the new config. (Whether this is done by change requests or in some other way is up to your organization.)
You may have noted that the audit columns created_by, created_date, updated_by, and updated_date are not referenced at all in the above script. Again, if you’re not interested in these you don’t have to use them. This particular organization had a standard that mandated having audit columns on every table.
Triggers: Keeping Things Consistent
Triggers ensure that these audit columns are consistently updated, no matter what the source of the SQL (scripts, your application, scheduled batch updates, ad-hoc updates, etc.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
My background is mostly Oracle and, unfortunately, Oracle limits identifiers to 30 bytes. To avoid exceeding this, each table is given a short alias of three to five characters and other table-related artifacts use that alias in their names. So, reference_value’s alias is reva – the first two characters from each word. Before row insert and before row update is abbreviated to bri and bru respectively. The sequence name reva_seq, and so forth.
Hand-coding triggers like this, table after table, requires a lot of demoralizing boiler-plate work for developers. Fortunately, these triggers can be created via code generation, but that’s the subject of another article!
The Importance of Keys
The ref_type_key and type_key columns are both limited to 30 bytes. This allows them to be used in PIVOT-type SQL queries (in Oracle. Other databases may not have the same identifier length restriction).
Because key uniqueness is ensured by the database and the trigger ensures that its value remains the same for all time, these keys can – and should – be used in queries and code to make them more legible. What do I mean by this? Well, instead of:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
You write:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
Basically, the key clearly spells out what the query is doing.
From LDM to PDM, with Room to Grow
The journey from LDM to PDM is not necessarily a straight road. Nor is it a direct transformation from one to the other. It’s a separate process that introduces its own considerations and its own concerns.
How do you model the reference data in your database?
