

In 2024 and beyond, new types of applications will require you to refresh your arsenal of data modeling techniques. Find out what challenges you will face and what database design patterns you can use to overcome them.
It is often said that just when you think you know all the answers, the universe comes along and changes all the questions. The universe of database design is no exception. Just when you think you have all the knowledge you need to design any type of database, new types of applications appear that pose new challenges for database modeling. And you must adapt to them in order to stay relevant as a data modeler.
There is no alternative but to constantly acquire new knowledge in order not to be outdated.
The good news is that you will be able to keep using the same database modeling tool you use these days – provided that tool is kept up to date with the latest technologies and allows you to abstract data models, as is the case with Vertabelo.
In this article, we’ll give you some help, pointing out how the best practices in database design will change from 2024 onwards. If you are new to the world of data modeling, I suggest you first find out how to learn database design before reading on.
Today’s Database Design Patterns
Despite the more than 50 years that have passed since their invention, relational databases are still going strong. The entity-relational design pattern – which is based on creating diagrams that represent real-world entities and the relationships between them – is still the most widely used for designing relational databases.
In recent years, NoSQL or non-relational databases have gained relevance. Their main virtue is the possibility of handling unstructured data; this makes them independent of the rigid pattern of entities, attributes, and relationships typical of the relational model. The document model, which stores data in JSON or XML documents, is one of the most common patterns in this context. This pattern offers great flexibility in data structures and is typical of NoSQL databases like MongoDB.
Another NoSQL database design pattern is the columnar model, which uses columns instead of rows as the unit of data storage. This facilitates the retrieval of subsets of data much more efficiently than the relational model. In addition, this pattern accommodates parallelism and scalability requirements – which will be among the future best practices in database design, as we will see below.
Finally, the graph model is another popular NoSQL database design pattern. It is used to represent complex relationships between data. Examples of the use of this pattern are data models for fraud analysis (which must analyze relationships and connections between large numbers of transactions) and data models for social networks. Specialized database managers like Neo4j, OrientDB, or Amazon Neptune are used to implement graph pattern models.
Database Design Trends in 2024
Evolving application architectures and emerging trends in software development are running up against the limitations of traditional database design patterns. Big Data and real-time data (RTD) are two examples of application types whose specific requirements force you to rethink the way you create your schemas.
Requirements like traceability, data quality, auditing, and versioning (among others) are critical for Big Data and RTD processes. Database design trends for 2024 will be tailored to meet these requirements. To clearly identify the design patterns to use, let’s start by looking at what’s needed in the different phases of these processes.
Database Design Patterns for Data Ingestion
The ingestion layer in a modern database architecture is responsible for collecting Big Data and storing it in a unified repository so that it can then be used for cleansing, processing, and analysis. Ingested data repositories can take various forms, such as data lakes, databases, and data warehouses. The main requirement of these repositories is the flexibility to assimilate unstructured information, coming from heterogeneous sources and with variable formats.
An example of a pattern for data ingestion is a schema for storing user events in real time. The advantage of this pattern is that it can scale to the level of tens of thousands of simultaneous users without missing any event. This pattern is characterized by having a minimum number of tables, with a central table capable of storing information without a prefixed structure.
In the entity-relationship diagram (ERD) depicted in the following example, there is a central table of events related to lookup tables of event types, users, and devices. In addition, it has a column that admits any kind of information. This column can be of TEXT, JSON, or XML type.
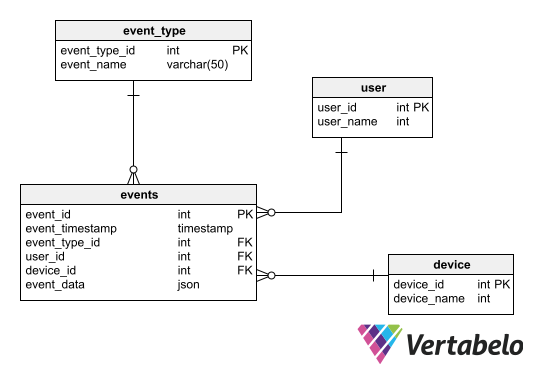
A basic schema for storing ingested real-time events data.
Depending on how the Big Data repository is implemented, data ingestion may not be done in real-time, but in batches. In such a case, it is necessary to add an identification of the source batch to the events table; this ensures data traceability. To replicate an ERD like the one in the example above, check out this article on how to draw a database schema from scratch.
Database Design Patterns for Metadata
Flexibility is a priority in data ingestion design patterns. Unfortunately, this brings with it the problem of increased data errors. That is why data ingestion repositories must undergo a cleaning and validation phase. As a result of this phase, you should have a consistent dataset with guaranteed integrity. This dataset can be incorporated into a modern database architecture with a pre-established structure.
The cleansing and validation processes of the information ingested by a Big Data repository requires a schema that responds to a metadata pattern. This schema serves as a reference so that the cleansing and validation processes know what formats the ingested data must have and what validation rules they must comply with. For example, a metadata schema may indicate the data type, maximum length, and mandatory nature of each element in a raw data repository. This metadata should reflect the structure of the final database, where the cleaned and validated data will end up.
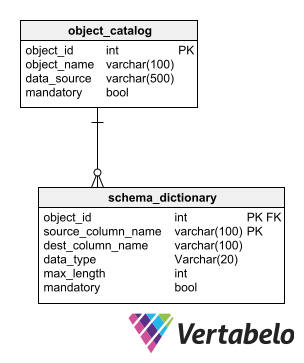
A basic metadata schema that stores the rules that source information in a Big Data repository must follow.
Microservices
Microservice architectures have become a decisive element in companies’ digital renaissance. This is because they allow monolithic applications to be divided into decoupled functional components that interact via APIs. This decoupling allows each microservice to scale independently, according to its particular needs. In addition, microservice architecture enables the encapsulation of functionality and data, providing potential fault isolation to prevent a failure in one service from propagating to its peers.
In terms of data persistence, microservices adopt a fundamental pattern called database-per-service. According to this pattern, the database is private to each microservice. If a microservice needs information that resides in another database, that information must be provided via APIs. To avoid the overhead of frequent API calls, it is common to use data duplication between different services, as we will see below.
The ideal way to implement the database-per-service pattern is for each service to have its own database server. To maximize availability – which is a fundamental feature of the architecture – it is common for microservices to use in-memory database engines (such as Redis or Memcached) that maximize performance on low-volume databases. However, this is not a requirement for microservices. Each can have a different database engine, even if they interact with each other and are part of the same system. One microservice may use a traditional RDBMS to record transactions in a normalized schema, while another accesses a NoSQL database for high-volume analytical queries.
As stated above, different microservices should not share a centralized database. If they did, they would not be free to scale independently and would generate multiple points of failure: if a failure in one microservice brings down a centralized database, all the other services that use that database would fail as well.
If several microservices must share a database for some reason, there must necessarily be a form of table partitioning that ensures that each set of tables belongs to a particular service. There should be no references between tables belonging to different partitions. One way to implement this (anti)pattern – and mitigate some of its drawbacks – would be to assign a different database user to each microservice. You’d then assign each user permissions only on the tables that belong to the corresponding service.
In the following example, four microservices that make up an e-commerce system share a partitioned database. The four microservices are:
- Product Catalog
- Order management
- Authentication and users
- Shopping cart
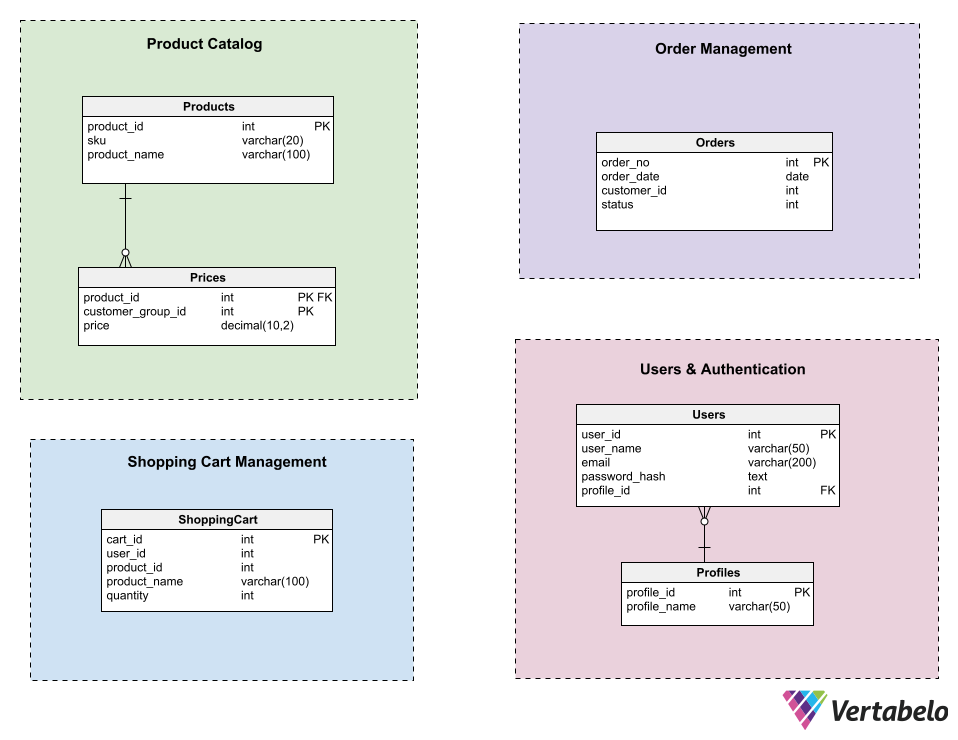
The subject areas in this diagram set the boundaries of the data model for each microservice. To maintain the encapsulation inherent to microservices, there should be no relationships involving tables that belong to different subject areas.
Although traditional database design principles will tempt you to establish relationships between tables belonging to different partitions to ensure referential integrity. For example, you may want to establish a foreign key relationship using product_id in the ShoppingCart and Products tables – but you cannot do so in the database-per-service pattern. In this pattern, it may also be desirable to introduce redundancy to minimize the necessity of continually calling APIs that degrade the performance of the service.
In the example above, the ShoppingCart table includes the product_name field to prevent the Shopping Cart service from having to call the Product Catalog service to get the name of each product. Check out these other database diagram examples that could be useful to illustrate these concepts.
Caching Patterns
REST (Representational State Transfer) APIs employ a set of architectural constraints aimed at optimizing the performance, scalability and modifiability of web services. In the REST architectural style, data and functionality are considered resources and are accessed using Uniform Resource Identifiers (URIs). In REST architectures, caching patterns are commonly used to optimize data access performance, leveraging in-memory database technologies like Redis, Memcached, or Hazelcast. In addition to achieving higher performance in the execution of APIs, the data cache pattern also serves to reduce the workload on centralized databases.
The commonly used pattern for implementing data caching is the key-value database. A key-value database is a method of data storage that takes the form of a large list of unique identifiers, each associated with a value. This pairing is known as a key-value pair. The key is what allows any data to be found quickly (as in any table in the relational model) and the value can be either the data itself or the location of that data.
A key-value database can be represented as a simple two-column table:
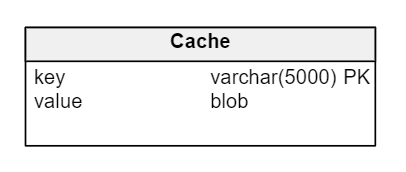
The structure of a key-value repository could be as simple as a table with two columns. Note that the column value must be of a data type large enough and flexible enough to accept practically anything.
To implement a cache that reduces reads to a centralized database, you can implement an in-memory key-value database that implements the data cache pattern and acts as a proxy to the main database. This database would store SQL queries as keys and the results of each query as values.
Scalability and Parallelism
Many of the database design patterns for 2024 compete to be the best suited to deliver the scalability and parallelism that are the “holy grails” of a new breed of applications. While there is no clear winner in this competition for scalability among design patterns, the columnar database pattern stands out in terms of user preference.
Columnar databases are inherently designed to provide parallelism and scalability. In columnar databases, each column of a table is stored separately, with all values in that column grouped together. In database systems like Snowflake or BigQuery, which implement the columnar pattern, data is stored column-wise and access to it is also column-wise.
In a columnar database with a Products table that has SKU and Price attributes, all SKUs are stored together, as are all prices. This allows optimized read operations that fetch data from only a subset of attributes and ignore the others. If you need to get all the SKUs in the table, the read can be done optimally by not having to traverse the table by rows.
The following example compares a Products table in traditional tabular format and the same data stored in columnar format:
The Products data stored in columnar format:
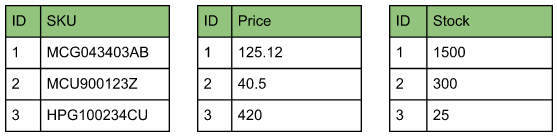
With the columnar storage pattern, adding new columns to a table can be done without affecting the existing columns. Another feature of this pattern is that it allows indexing, compressing or partitioning each column independently of the others, allowing for fine-grained optimization of performance and storage space.
In distributed data warehouses, the columnar database pattern allows partitioning data at the column level to parallelize read operations and scale horizontally over elastic platforms consisting of multiple nodes.
The bottom line is that there is no need to size the performance and storage of a database beforehand. Stored data can grow indefinitely by simply adding more nodes to the infrastructure, without affecting performance or efficiency.
Dealing with Change
Throughout this article, we have taken a look at the major trends in database design for 2024 onwards. The number of new names and new ideas may seem overwhelming. But let’s keep in mind that most of them are simply an evolution of database concepts that were developed decades ago.
To adapt to the new requirements imposed on us by the database design universe, we have to be willing to step out of our comfort zone – to leave behind the techniques that we have mastered and welcome new ones that will shape data modeling for years to come.
