

In a previous article we discussed the star schema model. The snowflake schema is next to the star schema in terms of its importance in data warehouse modeling. It was developed out of the star schema, and it offers some advantages over its predecessor. But these advantages come at a cost. In this article, we’ll discuss when and how to use the snowflake schema.
The Snowflake Schema
The snowflake schema’s name comes from the fact that dimension tables branch out and look something like a snowflake. When we look at the model above, we’ll notice it’s a fact table surrounded by a few dimension tables, some of which do the aforementioned branching. Unlike the star schema, dimension tables in the snowflake schema can have their own categories.
The ruling idea behind the snowflake schema is that dimension tables are completely normalized. Each dimension table can be described by one or more lookup tables. Each lookup table can be described by one or more additional lookup tables. This is repeated until the model is fully normalized. The process of normalizing star schema dimension tables is called snowflaking.
You’ll be hearing a lot about normalization in this article. What is normalization? Basically, it’s organizing a database in a way that minimizes redundancies and protects data integrity. Check out this post to learn more about normalization and denormalization.
Snowflake Schema Example: Sales Model
Previously, we used a star schema to model a fictional sales department – this would be akin to a data mart used to track sales activities and results. The model has five dimensions: product, time, store, sales type and employee. In the fact_sales table, price and quantity are stored and grouped based on values in dimension tables. For a refresher, have a look at the star schema sales model below:
Here is the same model organized as a snowflake schema:
The dim_employee and dim_sales_type dimension tables are exactly the same as in the star schema model because they are already normalized.
On the other hand, we applied normalization rules to the rest of the dimension tables.


The dim_product dimension table from the star schema is split into two tables in the snowflake model. The dim_product_type table was added to reference the matching type in the dim_product table. Using this, we avoided some data integrity problems.
It’s logical to assume that we’ll already have all of the product names and their related types inserted as part of the ETL process, but suppose we need to add more product names and types. In a star schema we could mistakenly enter the wrong product type into the table. In the snowflake schema:
- If we encounter new product type name, we can add a new product type and then relate that type to a newly added record. However, this could result in the user entering wrong information, just as in star schema.
- We could check to see if the product name that we want to add already exists. If so, we can get its ID; if not, a warning will come up asking us if we want to add a new product and a related type.

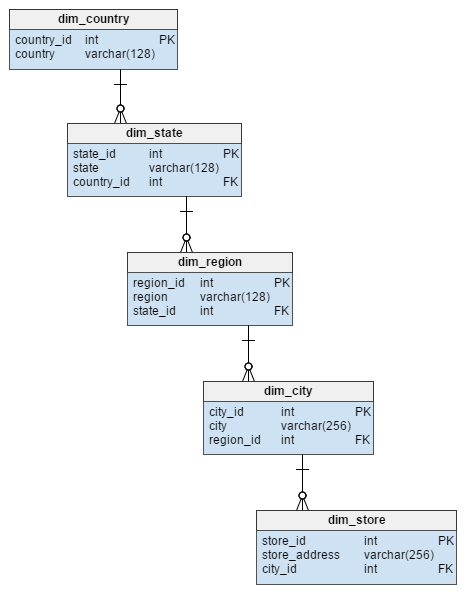
The dim_store dimension table from the star schema is represented by 5 tables in the snowflake schema. These divide the city, region, state and country attributes that were stored in the dim_store table. Normalizing this table not only avoided data integrity risk, it also saved some disk space.
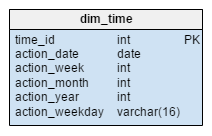
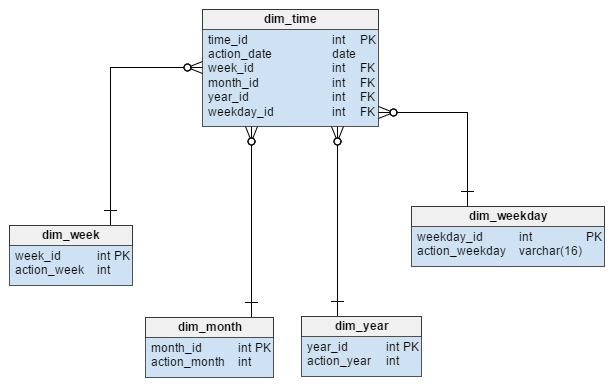
The dim_time dimension is represented with five tables. We can think of dim_week, dim_month, dim_year and the dim_weekday tables as dictionaries that describe the dim_time table.
The dim_week, dim_month, dim_year and dim_weekday tables are four different hierarchies used to describe our time dimension. We could add more dimensions like quarters or other related tables if we needed them. In this example, dim_month is a dictionary containing 12 months; from this dimension alone, we have no way of knowing which year that month belongs to; that’s the function of the dim_year table.
Snowflake Schema Example: Supply Orders Model
The other data mart we discussed was for supply orders. The idea is to store and aggregate all supply order data for the following four dimensions: product, time, supplier and employee. Once again, we’ll take a look at the relevant star schema:
Converting this to the snowflake schema, we get the following model:
The same normalization rules as those described for the sales model were used on the dim_product, dim_time and dim_supplier dimension tables.
Advantages and Disadvantages of the Snowflake Schema
There are two main advantages to the snowflake schema:
- Better data quality (data is more structured, so data integrity problems are reduced)
- Less disk space is used then in a denormalized model
The most notable disadvantage for the snowflake model is that it requires more complex queries. These queries, with their increased number of joins, could decrease performance significantly.
We’ll rewrite the same query used in the star schema article for the snowflake schema sales model. Here’s the query needed to return the quantity of all phone-type products type sold in Berlin stores in 2016:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
The Starflake Schema
A starflake schema is a combination of the snowflake and the star schemas. We can view it as a snowflake schema that has some dimension tables denormalized. When used correctly, the starflake schema can give a best-of-both-worlds approach. Obviously, the snowflake part of the model should save disk space, while the star part should improve performance.
The model above is basically a snowflake model with a denormalized dim_time table. Since this schema reduces the number of query joins needed, it could improve performance. On the other hand, we won’t lose a notable amount of the disk space, as most of the table attributes and foreign key attributes share the int type.
The Galaxy Schema
In data warehousing, a galaxy schema is when two or more fact tables share one or more dimension tables. One reason to use this schema is to save disk space. We’ve created a sample galaxy schema below:
Here, we have two fact tables, fact_sales and fact_supply_order, that directly share three dimension tables: dim_product, dim_employee and dim_time. Notice that even dim_store and dim_supplier share the same lookup table, dim_city.
We’ll save space this way, but we must have a few things in mind before we join two data marts (in this case, sales and supply orders) into one galaxy schema:
- Is there any logic behind joining them? E.g. Would both data marts be used by the same department?
- Are we sure that we need precisely the same dimension and granulation for both data marts?
The snowflake schema is often used in data modeling. It may be the right choice in situations where disk space is more important than performance. If we want a balance between space-saving and performance, we can use the starflake schema. Still, the right fit for any specific problem depends on many parameters. This is one of the areas in IT where we can ‘play’ with factors to come up with the best solution.
