 -
12 minutes read
-
12 minutes read
Where Does Database Modeling Fit in the Software Development Life Cycle?

Every software application uses stored data, whether it’s a simple list of user preferences or a complex database with a large number of tables and relationships. The importance of data modeling tasks within the software development life cycle is in direct proportion to the complexity of that stored data and its relevance to the application requirements.
In the case of an application that only stores a list of user preferences, database modeling tasks are minimal and can be handled by practically anyone. On the other hand, when an application uses a database with hundreds of tables, database modeling is a central and critical task. It will heavily influence whether that application meets its functional, performance, security, and other requirements.
Data Modeling as Part of the SDLC
At some point in the software development life cycle (SDLC), database modeling must take place. This task can begin and end within a specific segment of the project timeline, or it can span the entire duration of the SDLC. Either way, it should be aided by an automatic tool, such as the Vertabelo database modeler, to substantially shorten design and implementation times.
Depending on how the development team is assembled and which methodology is used, the time and the people involved in the creation of the data model may vary.
Development Team Roles
One of the key factors of a successful software project is that its roles and responsibilities are explicit and well-identified.
Not all software projects need the work team to be made up of the same roles. Long or complex projects commonly have greater granularity in the role breakdown, while short or simple projects can be delivered by a few individuals – or, in the simplest case, by two people: a sponsor and a programmer.
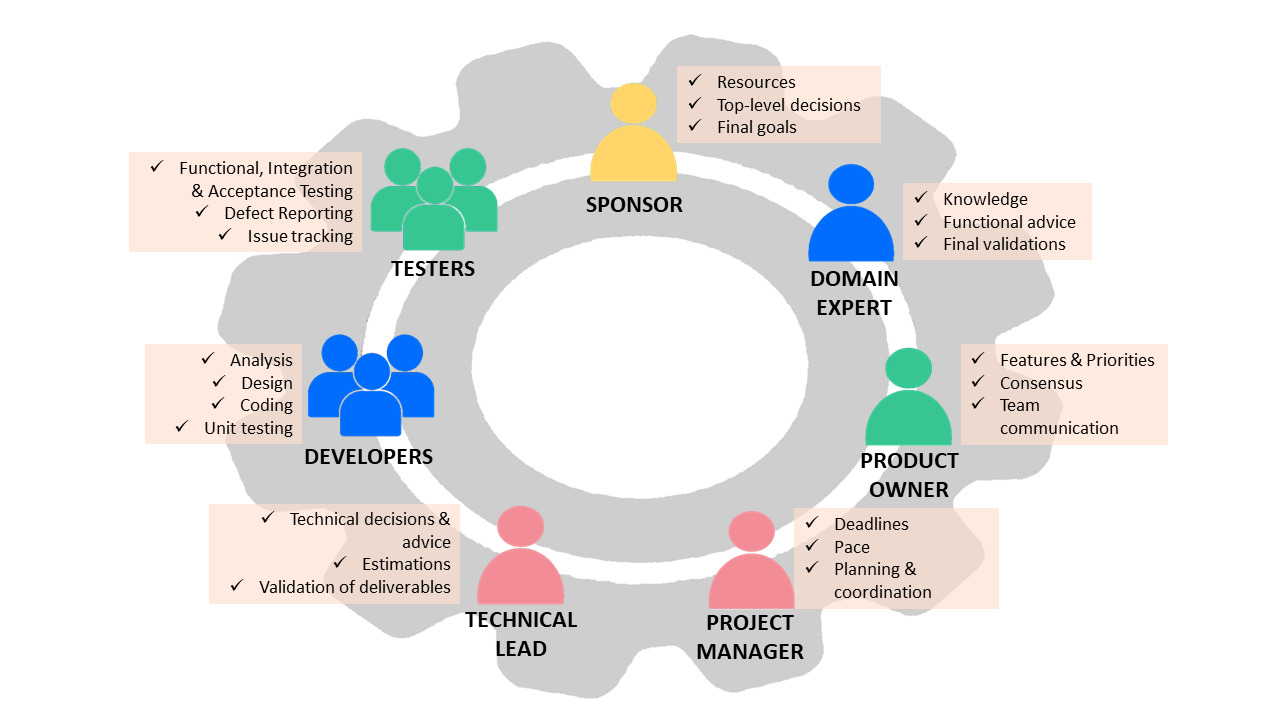
SDLC Roles and Responsibilities
The roles listed below are often found in average-sized software projects.
Sponsor
A sponsor is a person (or a group of people) who provides the resources for the project and states the final objectives. Sponsors have a high-level vision and take high-level decisions. They monitor the project without getting into technical aspects. Except in particular cases, such as the development of data-centric applications in which the data model is itself a final deliverable, sponsors rarely intervene in decisions that affect the data model.
Domain Expert (DE)
Also called subject matter experts (SME), DEs are experts in the business areas on which the application will have an impact. DEs are usually the ones who provide the knowledge to write the requirements. In relation to the data model, they provide the inputs for the creation of the conceptual, logical, and physical data models.
For example, suppose you are developing an application that maintains a customer directory. The domain expert will know if one or several telephone numbers need to be registered for each client. That will determine if Telephone is an attribute of the Client entity or if Telephones will be a separate entity with a one-to-many relation with the Client entity.
Regarding the physical model, DEs can advise on things like the best data type for a given field. Continuing with the example of the customer directory, the DE would define the maximum number of digits/characters for a Telephone_Number field.
Product Owner (PO)
The PO acts as a proxy for the business and the end-users. They help define the set of requirements included in each release of the software product to maximize team performance and project ROI. The PO is the point of contact for several roles within the team, ensuring that the objectives and activities of all stakeholders are aligned.
The PO’s main tasks have to do with follow-up and communication. In relation to data modeling, POs must ensure that the requirements defined by the DEs reach the person in charge of the design in a timely manner. They also check that these requirements are correctly interpreted so that the data model complies with them.
Project Manager (PM)
The PM acts like the project’s orchestra conductor, setting deadlines and knowing precisely who does what and when at all times. It is also the PM's responsibility to detect delays and unforeseen events and suggest solutions (e.g. adding more people to a task) so that deadlines and budgets are not affected. If there is no alternative but to change the deadlines and budgets, the PM negotiates with the sponsors for more money, more time, or both.
PMs don’t intervene in decisions that intrinsically affect data modeling tasks, but they determine when such tasks must start and when they must be finished.
Technical Lead (TL)
As the name implies, the TL leads the technical development team, which is made up of designers, coders, architects, and so on. A TL’s responsibilities include translating business requirements into a technical solution, guiding the development team on technical issues, estimating efforts for each development task, and communicating estimates, progress, and problems to the PM. The TL’s decisions define the technical paths to follow and the standards and practices that must be met.
When it comes to data modeling, the technical leader can decide, for example, which artifacts to use for analysis and design. A key TL decision would be whether to use an ERD or ORM to represent the data model. The TL also validates that the data model will meet requirements, identifies needs for changes or improvements, and transmits those needs to the database designer.
Developers
No need to say it, but I will anyway: Developers are the ones who do the hard work, turning requirement definitions into a functional software product. In addition, they provide the TL with estimates and statuses for the tasks under development.
Depending on the particularities of the project, several sub-roles can be distinguished within the group of developers, such as analysts, designers, architects, and coders. The designer role could be subdivided into UX / UI designer, architecture designer (or simply architect), and data model designer. Other data-related roles are often found in the development of data-centric solutions, such as data scientist, database analyst, and database administrator(DBA).
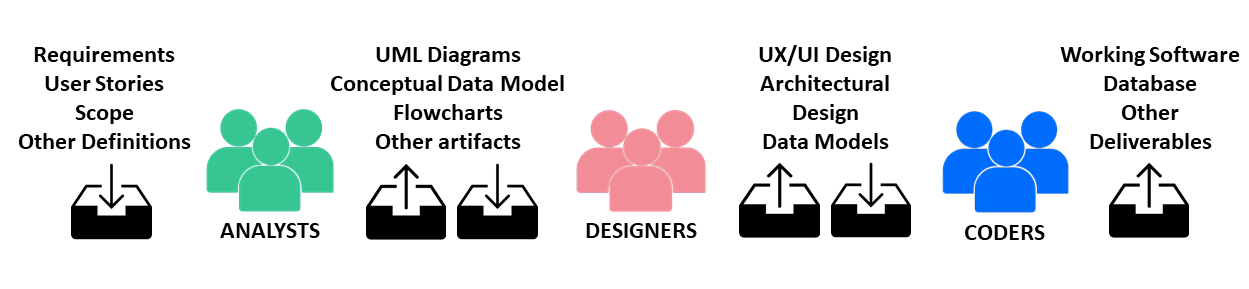
Typical Workflow Within a Development Team
It is common for different data models – conceptual, logical, and physical – to be created by different members of the development team. The conceptual model can be designed by a functional analyst, the logical by a data analyst, and the physical by the programmers themselves.
A healthy SDLC should have close collaboration and constant communication between the members of the developer team. Data model designers are part of this team, and their responsibilities include providing their colleagues with all the documentation and information necessary to use the model and the databases properly: ER diagrams, table structure definitions, views, stored procedures, and advice on how to run queries and operations for maximum efficiency. Data designers must also listen to their colleagues (and the TL) and respond to requests for changes or enhancements. They must be willing to work through changes to maximize the quality of the final software product.
Testers
They are in charge of testing the software product under development and reporting bugs. There are different kinds of testers, with different degrees of technical knowledge. Those with less technical knowledge act from the point of view of the end-user, carrying out functional and acceptance tests. Other testers, with greater technical knowledge, test running software and deliverables (e.g. class diagrams, source code, or ER diagrams). Technical testers can detect and report data model failures or report database performance issues so that the designer can optimize the data model.
Process Methodologies
Choosing the right process methodology is as important as defining the working group that will be in charge of the software development.
A Brief History of Process Methodologies
In the early days of software engineering, software development methodologies were inspired by those used in other engineering disciplines, such as civil engineering:
Requirements were defined. Analysis was carried out, followed by developing the design, then the programming, then testing and corrections, and finally deploying the finished version. Each phase of the process began when the previous one finished and was fed by the deliverables of its predecessor.
This model, commonly called the waterfall process, is the cause of all kinds of problems, such as unmet deadlines, insufficient budgets, and software that does not meet requirements. The basic problem with the waterfall model is that it does not recognize that changes – in requirements, technologies, and priorities – are something that software developers must constantly deal with.
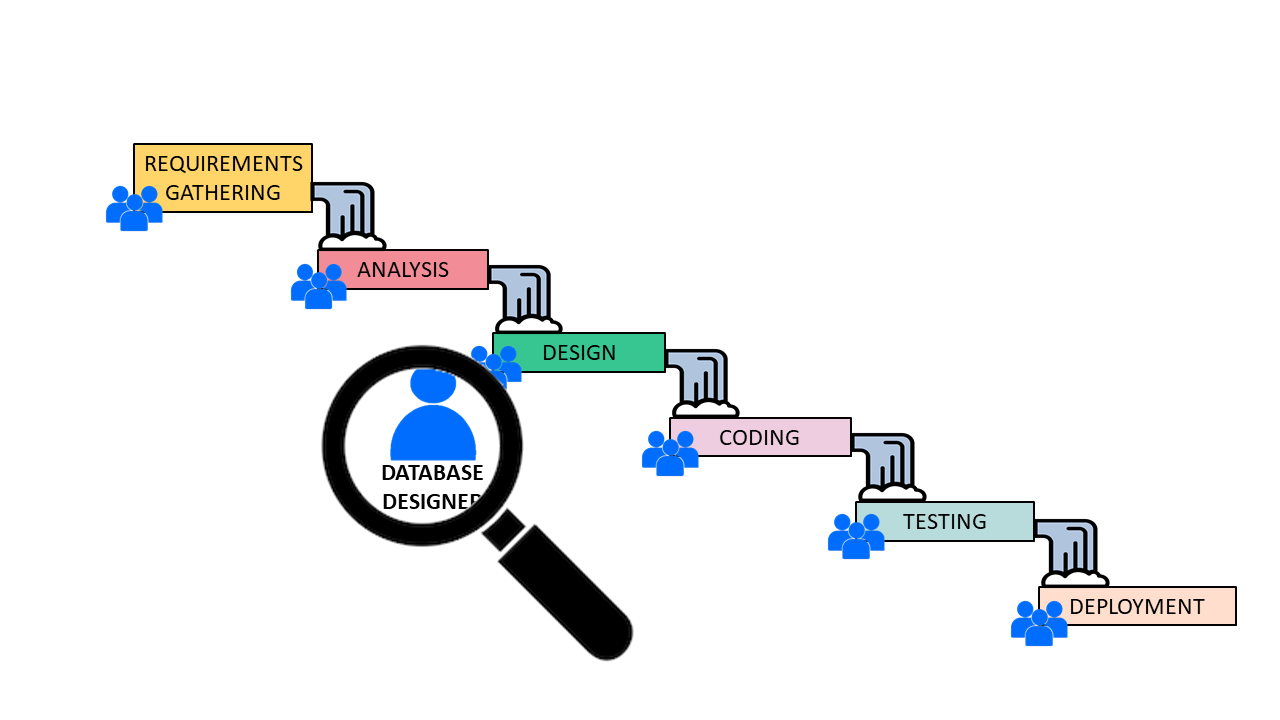
Database Modeling Within a Waterfall SDLC
In the waterfall model, the design of the data model is carried out within the design phase of the project. The data designer takes the documents generated in the previous phase of the project (requirements analysis), designs the data model, and passes it to the next stage (development). This way of working might be considered the most comfortable: data designers receive inputs to work with, put together the database model, and deliver it. If there are no objections to the artifacts delivered (e.g. ER diagrams, specifications, and other technical documents), their job is done.
In reality, this method represents a huge risk, as it has no margin for errors or changes. If a mistake is made or a wrong decision is taken in the design of the model, then the programmers must work on a faulty design – and the actual problem will be detected by end users when the product is finally deployed. The cost of a mistake or a bad decision is gigantic, since it implies redoing all stages of development from the source of the problem on.
Evolution of Traditional Methodologies
In an attempt to make the waterfall model more tolerant of changes and mistakes, variants were proposed, such as a waterfall model with feedback, which admits the possibility of reverting to an earlier phase when a need for corrections arises. Then the iterative models appeared, in which all the phases of the process are repeated as many times as necessary; in each iteration, a closer approximation to the desired final product is achieved.
Finally, Agile methodologies (Scrum, Extreme Programming, or Crystal) were adopted. Work in Agile methodologies is done within short, fixed periods of time (timeboxing) with the premise of determining, within each timebox (commonly called a sprint) a limited number of features (user stories) that must be completed (that is, analyzed, designed, programmed, tested, and delivered) within the time established for the sprint.
Agile methodologies welcome change rather than viewing it as a risk. They prioritize communication, collaboration, and shared responsibilities. In their little more than two decades of life, Agile methodologies have proved capable of achieving significant improvements in the quality of the software products developed – as well as being respectful of deadlines and budgets.
The Data Designer’s Role in Agile Methodologies
Good communication and strong interaction amongst the development team are decisive factors for the success of an Agile SDLC. In Scrum methodology, this idea is reflected in its name: in rugby, the scrum is a move in which the team depends on the strength of its ties to advance towards the realization of its objectives.

Database Modeling Within the Agile Pipeline
Following this concept, data modeling tasks are interrelated with the rest of the development and are carried out simultaneously. The data model designer is actively involved in development throughout the sprint, rather than acting on demand when their services are required. Coders and other designers go to the data designer to request information, clarify doubts, express needs, and propose changes. Testers sit next to the data designer to review models and do functionality and performance tests. Decisions regarding the data model are made by consensus and are the responsibility of the entire team, rather than resting solely on the shoulders of one designer.
Changes Happen
Imagine a situation that’s far more frequent than we’d like to admit: you’re designing the database for a software app that will manage the warehouse of an apparel manufacturer. You’re happy with the data model that you are creating. It is flawless and bulletproof. Developers love your ER diagrams and you’re happy to help them write more efficient queries and transactions. Everything is happiness until the PO arrives with terrible news: the company decided to rent a second warehouse and distribute the merchandise between the two of them. Now the system must manage two different warehouses instead of one and be able to report what merchandise is in each one.
Is it time to panic? That depends on the SDLC model the development team is using.
In a traditional model like the waterfall, panic is probably the way to go. Work must stop immediately. The PM must explain to the sponsor that the project should restart and return to square 1. It is necessary to redo practically everything done so far. The analysts must rewrite the requirements and redesign the conceptual, logical, and physical data models. The developers will remain idle until given the modified diagrams. Only then they will start rewriting a good part of their code, adjusting it to changes in the database and the new functionality.
The sponsor must decide if it is viable to extend the budget and deadlines or else accept that a defective software product will be delivered.
In an Agile SDLC, change is accepted as something normal. The new requirement is simply added to the product backlog. The development team continues to work as if nothing had happened until finishing the tasks of the current sprint. At the beginning of the next sprint, the entire team meets to review the product backlog, collectively estimate the effort required for the new requirements, and assign them a priority in relation to the rest of the backlog. If the project does not have room to extend the deadlines, the PO decides which items in the backlog are least necessary and can be eliminated from the project to make room for the new requirement, eventually leaving the least important for a future release. The sprint backlog is defined with the priority tasks, and the work continues as normal.
For the data model design to be adaptable to change, it must incorporate degrees of freedom using the principles of low coupling and high cohesion. This does not necessarily mean that the design will be more complex. Instead, it will allow decisions to be deferred until the last responsible moment. The last responsible moment strategy is used in Agile methodologies to avoid making premature decisions, keeping important or irreversible decisions open until the cost of not making a decision is considered to exceed the cost of making it.
Automation in Database Design Is a Must
Tools that automate the creation of data model diagrams, such as the Vertabelo data modeler, are vital to agility. They allow you to react to changes, document them with proper diagrams, and minimize the time and effort involved in altering models and adapting database schemas.
For a data model designer, always having a tool at hand that allows you to redesign models, validate them, and derive the necessary scripts to adapt the physical database is essential to maintaining fluid communication within the development team – and helping each member keep focused on their tasks. It is also a way to help the development team bring the SDLC to fruition within the deadlines and budgets established from the very beginning.
