

In an SQL database, the primary key is an essential part of any table. Choosing the right primary key for each table requires us to take different factors into consideration if we want to guarantee simplicity, adaptability, and performance.
A primary key (PK) is a specific type of database constraint. It guarantees that the column (or columns) that are part of it do not accept NULL values and that the value (or combination of values) entered for each row is unique. Tables may have multiple UNIQUE keys (which accept NULLs), but only one primary key. If you’re not familiar with keys in relational databases, I recommend reading the article On Keys to learn about what’s available.
It’s also important to note that primary keys can be single (i.e. made up of one column) or composite (made up of multiple columns). Because primary keys contain unique values, they are often used to create references between tables. For example, the ID column in the Driver table could be linked to the Driver_ID column in the Car table. In this case, Driver_ID is a foreign key column in the Car table that points to a related record in the Driver table. These two columns (primary key and foreign key) create a relationship between the two tables.
Factors that Influence Primary Key Choice
There are different factors to be considered when choosing a primary key. These are:
- Uniqueness. This is the most important It implies that no other row in the table has the same value (or combination of values) in this column (or combination of columns).
- Stability. Neither the definition (i.e. the column or columns making up the primary key) nor the values should change. Changing a PK’s columns would require redefining all the relevant foreign keys, while changing a PK column value would require updating all the referred rows in the child (related)
- Irreducibility. If you’re using a composite primary key, no one column or smaller combination of columns should uniquely identify each In other words, if you remove any column from the PK, the combination should stop being unique. Keep in mind that if you choose a composite primary key, your PK will be more complex and will use more resources (storage and memory).
- Simplicity. Use as few columns as possible, and choose columns with values that are easy to read and remember if you can.
- Columns with values that are familiar to the user make it easier for them to interact with the system.
Surrogate and Natural Primary Keys
Primary keys can be divided into two main categories:
- Surrogate keys use a system generated, business-agnostic column as an identifier for each row (e.g. an ID number assigned by the database).
- Natural keys (aka business keys) rely on existing attributes (e.g. a customer account number).
Each approach has advantages and disadvantages that we’ve already covered in this blog. See the articles Designing a Database: Should a Primary Key Be Natural or Surrogate?, What Is a Surrogate Key? and What Is a Business/Natural Key? for more information.
The fact that database engines allow both natural and surrogate keys means that there is no “one size fits all” primary key. In my experience, though, surrogate keys offer many benefits that make them the better choice in most scenarios.
Deciding on a Primary Key
Let’s review what to consider when deciding what columns to use as a primary key.
Surrogate or Natural Key?
The first thing to evaluate is whether to use a natural or a surrogate key. A quick analysis of the five factors mentioned previously will quickly demonstrate that while surrogate keys ensure that 4 of the 5 aspects are met, we cannot be 100% sure about this compliance when choosing a natural key:
| Key Factor | Surrogate Key | Natural Key |
|---|---|---|
| Uniqueness | Yes | Depends on Columns Selected and Business Definitions |
| Stability | Yes | Depends on Columns Selected and Business Definitions |
| Irreducibility | Yes | Depends on Columns Selected and Business Definitions |
| Simplicity | Yes | Depends on Columns Selected and Business Definitions |
| Familiarity | No | Depends on Columns Selected and Business Definitions |
|
Key Factor |
Surrogate Key |
Natural Key |
|
Uniqueness |
Yes |
Depends on Columns Selected and Business Definitions |
|
Stability |
Yes |
Depends on Columns Selected and Business Definitions |
|
Irreducibility |
Yes |
Depends on Columns Selected and Business Definitions |
|
Simplicity |
Yes |
Depends on Columns Selected and Business Definitions |
|
Familiarity |
No |
Depends on Columns Selected and Business Definitions |
Using an existing column or set of columns that currently comply with all five aspects does not guarantee that compliance will continue in the future if business or regulatory rules change. Unless you are 100% confident that a natural key complies with these criteria and will not change, I recommend designing your model using surrogate keys for most if not all your tables.
Data Type and Size
If you have chosen a natural key, then this decision will be based on the data type required for the values that you need to store, which is based on the business definition. But if you are using a surrogate key, then you need to choose the right data type and size for each of the keys. The most frequently-used data types for primary keys are:
- Numeric (integer). This is the simplest to use and to auto-populate. It uses less space than other data types (usually 1-8 bytes), thus both saving storage and enhancing JOIN and LOOKUP
- UUID/GUID (Universally Unique Identifier/Globally Unique Identifier). This type is also simple to auto-populate, but it’s completely unfriendly to users. Keys require 16 bytes of storage (and require more memory to perform JOINs and LOOKUPs). However, UUIDs and GUIDs are excellent for distributed environments. Some database engines provide a native data type for UUID values (g. UNIQUEIDENTIFIER in SQL Server), while others use a binary data type to store them.
- Alphanumeric: This type allows you to store ‘familiar’ values at the expense of space. Plus, they are usually difficult to auto-
Other data types are rarely used:
- Date/Datetime: These are easy to auto- However, there is no guarantee of uniqueness, since two
INSERToperations can occur at the same time. - Decimal: These are more complex than integer values and less simple to handle and interact with.
In the example below, we are going to see very simple model with the following tables:
CustomerTaxTypecontains customer tax classifications and is not administered by users. There are only a few values, so we will use the TINYINT datatype that allows us to store up to 255 values using only one byte per row.Customercontains details like name, account ID number, and tax ID number. Although customers can usually be uniquely identified by aTaxNumber, we decided to use a surrogate key of the INT data type; this allows us to store more than 2 billion values using only four bytes per row.SalesOrdercontains order data. Since our sales representatives travel a lot and generate orders while visiting our customers, we want them to be able to generate orders on their devices even if they aren’t connected to the corporate database. To facilitate this, they use a database installed on their device and upload the orders once they get back to the office. To allow unique values to be generated in each local database, we decided to use a UUID data type (UNIQUEIDENTIFIER in SQL Server) as the primary key for this
Populating a Primary Key
If you have chosen a natural key, this question is completely irrelevant; the PK columns will have the business values provided by the user or by an external system. For example, in a Passenger table that uses natural keys, a combination of the PassportCountry and PassportNumber columns can be used. Note that these values are not generated or calculated by the database but are provided by the passengers.
For surrogate keys, how to generate the primary key values is another important factor. Most database engines provide ways to automatically assign column values when a row is inserted:
- Identity is a column-level feature that automatically assigns a unique, sequential number to each row inserted. Only one column per table (usually the primary key) can have the identity feature enabled.
- Default is a database constraint that allows us to define a value to be placed into a column when a new row is inserted. This value can be fixed (not a choice for a primary key) or it can be generated by a:
- Sequence: A sequence is a database object that provides unique sequential numeric values. A sequence is not associated with any table or column (as an identity is) and can be used for more than one table. For example, the same sequence can be used to generate values for the
PurchaseandSaletables; values are unique not only in tables but across them.) - Function: You can use either system-provided or user-defined functions to return values for the primary key SQL Server provides functions like
NEWID()andNEWSEQUENTIALID()that return UNIQUEIDENTIFIER values for GUID / UUID columns.
- Sequence: A sequence is a database object that provides unique sequential numeric values. A sequence is not associated with any table or column (as an identity is) and can be used for more than one table. For example, the same sequence can be used to generate values for the
- Trigger is a program unit that is defined in the database and automatically executed when an INSERT, UPDATE, or DELETE operation is done on a table. To use a trigger to populate a primary key, an INSERT trigger needs to be defined on a table. It should include a command to populate the desired column using either a function or a sequence, as described above. Like defaults, triggers can be used to populate columns of any data type.
Continuing the sample model shown above, we are now using different ways to populate the primary key columns, as shown below. (You can click on the images to see them online on a Vertabelo diagram.)
- In the tables
CustomerTaxTypeandCustomer, we’ll use an identity – usually the best option for numeric surrogate primary key The Identity feature also allows us to define an initial (seed) value and an increment; both are set to 1 by default.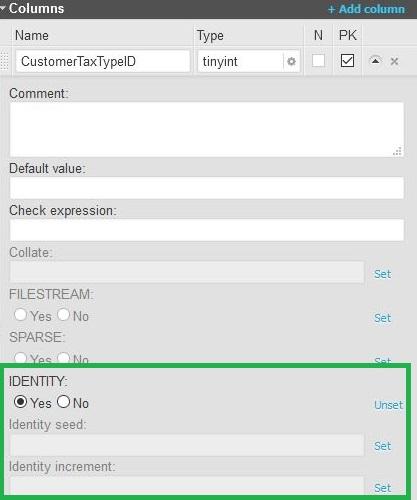
- In the
SalesOrdertable, we are using UNIQUEIDENTIFIER. Thus, we cannot use an identity, so we are going to define a DEFAULT value for the column. We’ll do this by using the NEWID() function, which automatically generates a unique GUID value.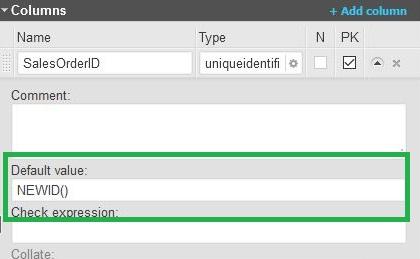
Note: You should consider using the available population options in the order listed. An identity is the best option for numeric data types, since it is simple, automatic, and has almost no performance impact. Defaults should be chosen over triggers for other data types, since using triggers implies executing a piece of code and can have a measurable performance impact. Read the article What Are the Different Types of Constraints in Databases to learn more about DEFAULT constraints and how to use them.
Avoid These Primary Key Problems
Over the years, I have seen (and sometimes made) some bad primary key definitions. Let me tell you about some of them and explain why I consider them bad decisions.
Surrogate Keys
When you’re using a surrogate key, there are some things that can go wrong (although not as frequently as with natural primary keys). Such mistakes fall into three categories:
- Bad data type selection: Sometimes designers try to keep all primary key columns of a homogeneous data type. Using the same data type (like GUIDs) for all table PKs – even when that table doesn’t receive INSERT operations in a distributed environment – wastes space and can negatively impact performance. Tables containing country, tax rate, or product price info are usually administered in headquarters and do not require a 16-byte GUID. Instead of prioritizing simplicity above all else, consider long term performance and storage consumption.
- Over-sizing: For example, imagine using BIGINT for all table primary key Using BIGINT will not be an issue on the parent table, since a few extra bytes on a dozen or so rows make no difference at all. However, it can have a huge impact on the child (transactional) tables (e.g.
Orders) that store millions or even billions of rows. - Under-sizing: Avoid using a data type that just barely works for current estimations; it can quickly become too small to store values when the database starts growing. This can be a nightmare for an operations team that suddenly finds they cannot enter new orders because the data type for that table’s primary key has reached its limit!
Natural Key Examples
The factors mentioned for surrogate keys that can also affect natural keys. In addition, there is always the chance that some business rule, business decision, or regulation will change, leading to problems like these:
- Uniqueness: A company decided to use
ProductCodeas the primary key for the Product table; the code was generated with a formula that ensured uniqueness and most users knew how to identify a product by its code. (For example, BL-TS-01 meant a blue t-shirt in size 1). Later, this company bought out a competitor. When trying to unify their systems, they discovered that both companies had different products with the same codes! The only way to solve this is to either add a company/brand identifier to the code (changing the code format, and thus changing all the data) or adding a company/brand column to the primary key and all the related tables (and thus changing the data model) – both very expensive options! - Reinventing the Wheel: This is an example that I personally saw many years ago. A company had offices in two countries. They used the same internally developed system on two completely separate databases (one in each country) and never shared any data. Eventually, they needed to start sharing some of the data (g. customer data) between countries; they found many customers with the same ID on both databases.
If I had to deal with that problem, I would have chosen one of these options:
- Adding a new two-character column representing the country (or database) where the row was created and creating a composite PK with the existing ID and the new country column.
- Adding a GUID column as the primary key.
Nevertheless, someone decided that the best way to ensure uniqueness in a new “distributed” configuration was to create a new column that concatenated the existing auto-generated identity column with the name of the user executing the insert and the timestamp of the insert operation. The new VARCHAR column stored information like “51749/John Smith/2021-04-12 15:24:33.573” or “14514/Laura Thompson/2020-09-21 05:44:31.117” – one of the strangest things I’ve ever seen on a database!
Are You Ready to Start Modeling Primary Keys?
We have just reviewed what primary keys are and what needs to be considered when choosing their columns. We have also seen some practical examples on Vertabelo. Now it’s time for you to start creating your own data models using the Vertabelo Database Modeler.
