

This is the third of our multi-part series on applying information security approaches to data modeling. The series uses a simple data model, something to manage social clubs and interest groups, to provide the content we look to secure. Later we will address modeling for authorization and user management, as well as other parts of a secure database implementation.
In social situations, it’s common to “read between the lines” – deducing the unspoken assumptions and assertions in a conversation. The same occurs in creating software and storing data in a database. Invoices are enumerated with the customer ID embedded, and how many data entities use a date-time as part of the key? It’s hard to imagine thoroughly documenting or structuring everything without some type of omission. But in our last instalment, we went through exactly that exercise. We were able to ascribe sensitivity to several parts of our social club database. But to quantify and manage that sensitivity, we must augment the structure of our data model in order to make the sensitive data and its relationships clear.
Closing Data Model Gaps
Data modeling for security necessitates several distinct varieties of structure changes. We are exploring these in turn, using a (very!) simple social club data model as our base for this series. As we have proceeded, we’ve enhanced the model with more data. In the last instalment, we analyzed the model to ascribe data sensitivity where we found it. This analysis also revealed that there were places where the data model indicated links that were not actually captured explicitly in columns and key relationships. The modeler should expect this in a security analysis. Moving forward from these discoveries, we will make these relationships as concrete and clear as possible by building out the tables and the connections between them. This will allow us to attach security attributes further on.
Building Out the Data Relationships in the Club
All the relationships in the data, as well as the data entities themselves, must have some representation in order to ascribe value or sensitivity to them. New columns, new keys, new references, even new tables may be needed to accomplish this. When we analyzed the tables and their relationships in our last post, we isolated two main tables with high-sensitivity data:
PersonPhoto
In addition, we had four containing data that was moderately sensitive:
MemberClubOfficeClub_Office
These aspects of sensitivity are partly intrinsic to each table, but non-explicit relationships carry a lot of the sensitivity. To attach it, we start to record the relationships and give them a structure to contain the sensitivity.
Relationships Embedded in Photos
Photo contains a lot of embedded relationships we need to capture. Mainly, we are interested in the relationship with Person. To capture the Person-Photo relationship, I am adding the Photo_Content table:
There are a lot of different aspects by which a Person may relate to a Photo. I decided to add a new table, Photo_Content_Role, to characterize the relationship of a Photo to a Person. Rather than have separate tables for each sort of relationship, we use a single connecting table and the Photo_Content_Role table. This table is a reference list with standard relationships like what we’ve already noted. Here is our initial set of data for Photo_Content_Role:
| Label | Max per Person | Description |
|---|---|---|
| Photographer | 1 | The person who actually took the photo |
| Depicted Person | 1 | A person recognizable in the photo |
| Copyright Owner | 1 | A person holding the copyright for the photo |
| Licensor | 1 | A party who has licensed the club’s use of this photo |
| Copyright broker | 1 | A party who resolved copyright issues for this photo |
| Object depicted | unlimited | content_headline identifies the object, content_detailed elaborates it |
| Comment | unlimited |
OK, so this is a bait-and-switch. I said Photo_Content would relate people to photos, so why is there something about “object depicted”? Logically, there will be photos where we would describe the content without identifying a Person. Should I add another table for this, with a separate set of content roles? I decided not. Instead, I will add a null person row to the Person table as seed data, and have non-person content refer to that person. (Yes, programmers, it’s a little more work. You’re welcome.) The ‘null Person’ will have id zero (0).
Key Learning No. 1:
Minimize tables with sensitive data by overlaying similar relationship structures into a single table.
I anticipate there may be additional relationships that will be discovered downstream. And it’s also possible that a social club may have its own roles to ascribe to a Person in a Photo. For that reason, I have used a ‘pure’ surrogate primary key for Photo_Content_Role, and also added an optional foreign key to Club. This will allow us to support special uses by individual clubs. I call the field ‘exclusive’ to indicate it should not be available to other clubs.
Key Learning No. 2:
When end users might extend a built-in list, give its table a pure surrogate key to avoid data collisions.
Photo_Content_Role.max_per_person may also be mysterious. You can’t see it in the diagram, but Photo_Content_Role.id carries its own unique constraint without max_per_person. In essence, the real primary key is just id. By adding max_per_person to id in the primary key, I force each referring table to uptake information by which it can (should!) enforce a cardinality check constraint. Here is the check constraint in Photo_Content.
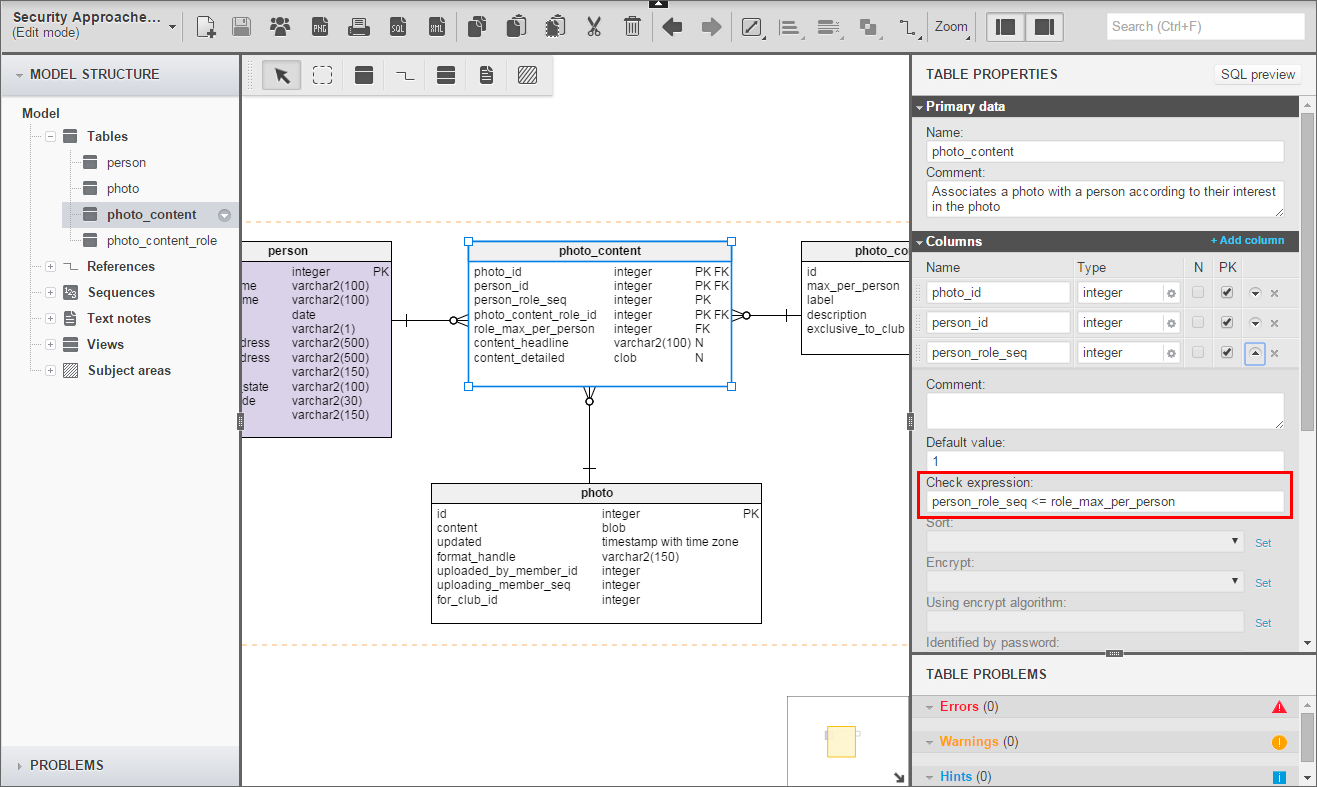
Key Learning No. 3:
When each row of a table has individual restrictions, referring tables must add a new unique constraint, extending a natural key with the constraint fields. Have the child table refer to that key.
Let’s look some more at Photo_Content. This is primarily a relationship between Photo and Person, with the relationship specified by the attached content role. As I noted before, however, this is where we store all descriptive information about the photo. To accommodate this sort of open-endedness, we have the optional content_headline and content_detailed columns. These will seldom be needed for an ordinary association between a Person and a Photo. But a headline like ‘Bob Januskis Receives the Annual Achievement Award’ is easy to anticipate. Also if there is no Person — ‘Object Depicted’, Person 0 — we must require something in the content_headline, such as ‘Northwest Slope of Mt. Ararat.’
The Last Missing Photo Relationship: Albums
So far, we haven’t added anything that relates Photos to Photos. It’s a big thing for social networks and photo services: Albums. And you wouldn’t want them in the proverbial shoebox, would you? So let’s fill in this glaring gap – but let’s think about it, too.
Album attaches Photos in a different way than the other relationships we’ve covered. Photos may be associated by the same club, a similar date, nearby GPS coordinates, the same photographer, and so on. However, Album clearly indicates that the enclosed Photos are part of a single topic or story. As such, the security-relevant aspects of one Photo may be inferred from another in the Album. Also, the ordering may amplify or diminish those inferences. So don’t just think of Album as an innocuous collection. Relating Photos is anything but.
Although not innocuous from a security standpoint, Album is a straightforward entity with a pure Id surrogate key owned by a Club (not a Person). Album_Photo gives us a set of Photos sequenced by Photo_Order. You’ll notice that I’ve made the Album id and order the primary key. The relationship is really between the Photo and the Album, so why not make those the primary key? Because odd cases requiring a Photo to repeat in an Album are certainly possible. So I put Photo_Order into the primary key, and after some thought, decided to add an alternate unique key with album and photo to prevent a Photo from repeating in an Album. If enough cries for repeating a Photo in an Album arise, a unique key is easier to remove than a primary key.
Key Learning No. 4:
For the primary key, select a candidate key with the least risk of being discarded later.
Photo Metadata
The last potentially-sensitive information to add is the metadata (usually created by whatever device has taken the photos). This data is not part of a relationship, but it is intrinsic to the photo. The primary definition of information a camera stores with a photo is EXIF, an industry standard from Japan (JEITA). EXIF is extensible and can support dozens or hundreds of fields, none of which can be required from our uploaded images. This non-required status is because these fields are not common to all photo formats and can be erased before uploading. I have built out Photo with many commonly-used fields, including:
- camera_mfr
- camera_model
- camera_software_version
- image_x_resolution
- image_y_resolution
- image_resolution_unit
- image_exposure_time
- camera_aperture_f
- GPSLatitude
- GPSLongitude
- GPSAltitude
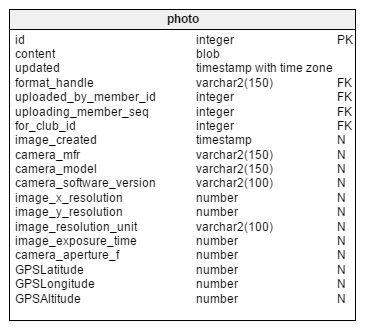
The GPS fields are, naturally enough, the ones which add the highest sensitivity to a Photo.
Our Model, with All Sensitive and Valuable Data Defined
We complete this phase of securing the club database with these changes. All the connections and the additional data needed are present, as depicted below. I’ve made Photo information red, and Album light turquoise to convey my idea of logical groupings. The augmentation of data elements is real, but very much minimized.
Conclusion
Putting any data model onto a good security footing requires an orderly and systematic application of security principles as well as relational database practice. In this instalment, we have reviewed the data model and carefully filled in missing structure that was implied, but not expressed in the schema. We could not assign value or provide protection for the existing data without adding the data that fills it in and correctly ties it together. With this in place, we will proceed to attach the elements of data valuation and data sensitivity that will allow us to clearly see all of the data from a complete security perspective. But that’s in our next article.
