

You’ve probably made some of these mistakes when you were starting your database design career. Maybe you’re still making them, or you’ll make some in the future. We can’t go back in time and help you undo your errors, but we can save you from some future (or present) headaches.
Reading this article might save you many hours spent fixing design and code problems, so let’s dive in. I’ve split the list of errors into two main groups: those that are non-technical in nature and those that are strictly technical. Both these groups are an important part of database design.
Obviously, if you don’t have technical skills, you won’t know how to do something. It’s not surprising to see these errors on the list. But non-technical skills? People may forget about them, but these skills are also a very important part of the design process. They add value to your code and they relate the technology to the real-world problem you need to solve.
So, let’s start with the non-technical issues first, then move to the technical ones.
Non-Technical Database Design Errors
#1 Poor Planning
This is definitely a non-technical problem, but it is a major and common issue. We all get excited when a new project starts and, going into it, everything looks great. At the start, the project is still a blank page and you and your client are happy to begin working on something that will create a better future for both of you. This is all great, and a great future will probably be the final result. But still, we need to stay focused. This is the part of the project where we can make crucial mistakes.
Before you sit down to draw a data model, you need to be sure that:
- You’re completely aware of what your client does (i.e. their business plans related to this project and also their overall picture) and what they want this project to achieve now and in the future.
- You understand the business process and, if or when needed, you’re ready to make suggestions to simplify and improve it ( e.g. to increase efficiency and income, reduce costs and working hours, etc).
- You understand the data flow in the client’s company. Ideally, you’d know every detail: who works with the data, who makes changes, which reports are needed, when and why all of this happens.
- You can use the language/terminology your client uses. While you might or might not be an expert in their area, your client definitely is. Ask them to explain what you don’t understand. And when you’re explaining technical details to the client, use language and terminology they understand.
- You know which technologies you’ll use, from the database engine and programming languages to other tools. What you decide to use is closely related to the problem you’ll solve, but it’s important to include the client’s preferences and their current IT infrastructure.
During the planning phase, you should get answers to these questions:
- Which tables will be the central tables in your model? You’ll probably have a few of them, while the other tables will be some of the usual ones (e.g. user_account, role). Don’t forget about dictionaries and relations between tables.
- What names will be used for tables in the model? Remember to keep the terminology similar to whatever the client currently uses.
- What rules will apply when naming tables and other objects? (See Point 4 about naming conventions.)
- How long will the whole project take? This is important, both for your schedule and for the client’s timeline.
Only when you have all these answers are you ready to share an initial solution to the problem. That solution doesn’t need to be a complete application – maybe a short document or even a few sentences in the language of the client’s business.
Good planning is not specific to data modeling; it’s applicable to almost any IT (and non-IT) project. Skipping is only an option if 1) you have a really small project; 2) the tasks and goals are clear, and 3) you’re in a real hurry. A historical example is the Sputnik 1 launching engineers giving verbal instructions to the technicians who were assembling it. The project was in a rush because of the news that the US was planning to launch their own satellite soon – but I guess you won’t be in such a hurry.
#2 Insufficient Communication with Clients and Developers
When you start the database design process, you’ll probably understand most of the main requirements. Some are very common regardless of the business, e.g. user roles and statuses. On the other hand, some tables in your model will be quite specific. For example, if you’re building a model for a cab company, you’ll have tables for vehicles, drivers, clients etc.
Still, not everything will be obvious at the start of a project. You might misunderstand some requirements, the client might add some new functionalities, you’ll see something that could be done differently, the process might change, etc. All of these cause changes in the model. Most changes require adding new tables, but sometimes you’ll be removing or modifying tables. If you’ve already started writing code which uses these tables, you’ll need to rewrite that code as well.
To reduce the time spent on unexpected changes, you should:
- Talk with developers and clients and don’t be afraid to ask vital business questions. When you think you’re ready to start, ask yourself Is situation X covered in our database? The client is currently doing Y this way; do we expect a change in the near future? Once we’re confident our model has the capability to store everything we need in the right manner, we can start coding.
- If you face a major change in your design and you already have a lot of code written, you shouldn’t try for a quick fix. Do it as it should have been done, no matter what the current situation. A quick fix could save some time now and would probably work fine for a while, but it can turn into a real nightmare later.
- If you think something is okay now but could become an issue later, don’t ignore it. Analyze that area and implement changes if they will improve the system’s quality and performance. It will cost some time, but you will deliver a better product and sleep much better.
If you try to avoid making changes in your data model when you see a potential problem — or if you opt for a quick fix instead of doing it properly — you’ll pay for that sooner or later.
Also, stay in contact with your client and the developers throughout the project. Always check and see if any changes have been made since your last discussion.
#3 Poor or Missing Documentation
For most of us, documentation comes at the end of the project. If we’re well-organized, we’ve probably documented things along the way and we’ll only need to wrap everything up. But honestly, that’s usually not the case. Writing documentation happens just before the project is closed — and just after we’re mentally done with that data model!
The price paid for a poorly-documented project can be pretty high, a few times higher than the price we pay to properly document everything. Imagine finding a bug a few months after you’ve closed the project. Because you didn’t properly document, you don’t know where to start.
As you’re working , don’t forget to write comments. Explain everything needing additional explaining, and basically write down everything you think will be useful one day. You never know if or when you’ll need that extra info.
Technical Database Design Mistakes
#4 Not Using a Naming Convention
You never know for sure how long a project will last and if you’ll have more than one person working on the data model. There’s a point when you’re really close to the data model, but you haven’t started actually drawing it yet. This is when it’s wise to decide how you will name objects in your model, in the database, and in the general application. Before modeling, you should know:
- Are table names singular or plural?
- Will we group tables using names? (E.g. all client-related tables contain “client_”, all task-related tables contain “task_”, etc.)
- Will we use uppercase and lowercase letters, or just lowercase?
- What name will we use for the ID columns? (Most likely, it will be “id”.)
- How will we name foreign keys? (Most likely “id_” and the name of the referenced table.)
Compare part of a model that doesn't use naming conventions with the same part that does use naming conventions, as shown below:
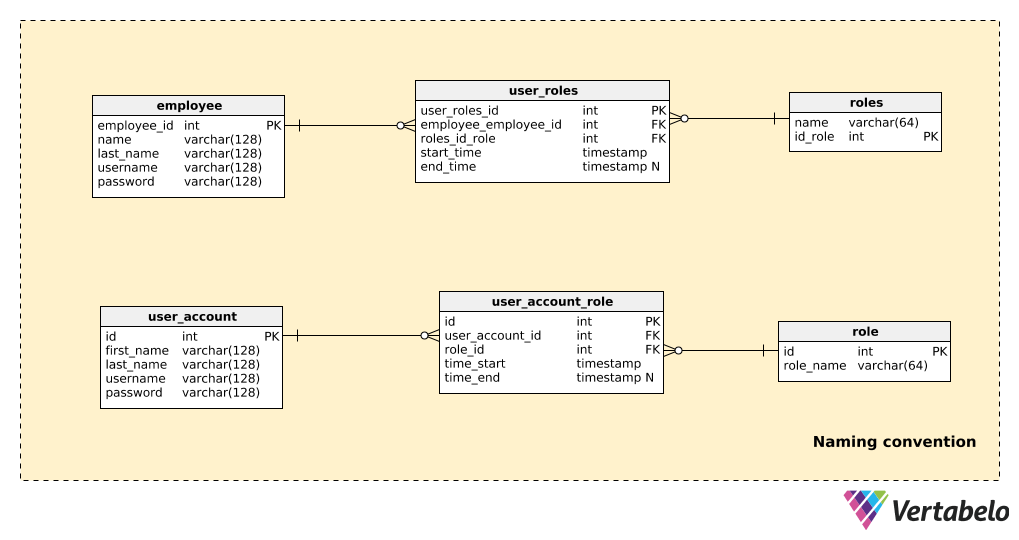
There are only a few tables here, but it’s still pretty obvious which model is easier to read. Notice that:
- Both models “work”, so there are no problems on the technical side.
- In the non-naming-convention example (the upper three tables), there are a few things that significantly impact readability: using both singular and plural forms in the table names; non-standardized primary key names (
employees_id,id_role); and attributes in different tables share the same name (e.g. name appears in both the “employee” and the “roles” tables).
Now imagine the mess would we create if our model contained hundreds of tables. Maybe we could work with such a model (if we created it ourselves) but we would make somebody very unlucky if they had to work on it after us.
To avoid future problems with names, don’t use SQL reserved words, special characters, or spaces in them.
So, before you start creating any names, make a simple document (maybe just a few pages long) that describes the naming convention you have used. This will increase the readability of the whole model and simplify future work.
You can read more about naming conventions in these two articles:
- Naming Conventions in Database Modeling
- An Unemotional Logical Look at SQL Server Naming Conventions
#5 Normalization Issues
Normalization is an essential part of database design. Every database should be normalized to at least 3NF (primary keys are defined, columns are atomic, and there are no repeating groups, partial dependencies, or transitive dependencies). This reduces data duplication and ensures referential integrity.
You can read more about normalization in this article. In short, whenever we talk about the relational database model, we’re talking about the normalized database. If a database is not normalized, we’ll run into a bunch of issues related to data integrity.
In some cases, we may want to denormalize our database. If you do this, have a really good reason. You can read more about database denormalization here.
#6 Using the Entity-Attribute-Value (EAV) Model
EAV stands for entity-attribute-value. This structure can be used to store additional data about anything in our model. Let’s take a look at one example.
Suppose that we want to store some additional customer attributes. The “customer” table is our entity, the “attribute” table is obviously our attribute, and the “attribute_value” table contains the value of that attribute for that customer.
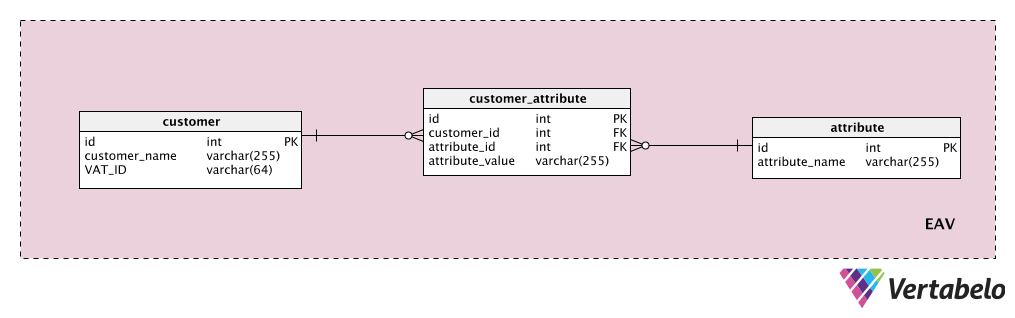
First, we’ll add a dictionary with a list of all the possible properties we could assign to a customer. This is the “attribute” table. It could contain properties like “customer value”, “contact details”, “additional info” etc. The “customer_attribute” table contains a list of all attributes, with values, for each customer. For each customer, we’ll only have records for the attributes they have, and we’ll store the “attribute_value” for that attribute.
This could seem really great. It would allow us to add new properties easily (because we add them as values in the “customer_attribute” table). Thus, we would avoid making changes in the database. Almost too good to be true.
And it is too good. While the model will store the data we need, working with such data is much more complicated. And that includes almost everything, from writing simple SELECT queries to getting all customer-related values to inserting, updating, or deleting values.
In short, we should avoid the EAV structure. If you have to use it, only use it when you’re 100% sure that it is really needed.
#7 Using a GUID/UUID as the Primary Key
A GUID (Globally Unique Identifier) is a 128-bit number generated according to rules defined in RFC 4122. They are sometimes also known as UUIDs (Universally Unique Identifiers). The main advantage of a GUID is that it’s unique; the chance of you hitting the same GUID twice is really unlikely. Therefore, GUIDs seem like a great candidate for the primary key column. But that’s not the case.
A general rule for primary keys is that we use an integer column with the autoincrement property set to “yes”. This will add data in sequential order to the primary key and provide optimal performance. Without a sequential key or a timestamp, there’s no way to know which data was inserted first. This issue also arises when we use UNIQUE real-world values (e.g. a VAT ID). While they hold UNIQUE values, they don’t make good primary keys. Use them as alternate keys instead.
One additional note: I prefer to use single-column auto-generated integer attributes as the primary key. It’s definitely the best practice. I recommend that you avoid using composite primary keys.
#8 Insufficient Indexing
Indexes are a very important part of working with databases, but a thorough discussion of them is outside of the scope of this article. Fortunately, we already have a few articles related to indexes you can check out to learn more:- What Is a Database Index?
- All About Indexes: The Very Basics
- All About Indexes Part 2: MySQL Index Structure and Performance
The short version is that I recommend you add an index wherever you expect it’ll be needed. You can also add them after the database is in production if you see that adding index in a certain spot will improve performance.
#9 Redundant Data
Redundant data should generally be avoided in any model. It not only takes up additional disk space but it also greatly increases the chances of data integrity problems. If something has to be redundant, we should take care that the original data and the “copy” are always in consistent states. In fact, there are some situations where redundant data is desirable:
- In some cases, we have to assign priority to a certain action — and to make this happen, we have to perform complex calculations. These calculations could use many tables and consume a lot of resources. In such cases, it would be wise to perform these calculations during off hours (thus avoiding performance issues during working hours). If we do it this way, we could store that calculated value and use it later without having to recalculate it. Of course, the value is redundant; however, what we gain in performance is significantly more than what we lose (some hard drive space).
- We may also store a small set of reporting data inside the database. For example, at the end of the day, we’ll store the number of calls we made that day, the number of successful sales, etc. Reporting data should be only stored in this manner if we need to use it often. Once again, we’ll lose a little hard drive space, but we’ll avoid recalculating data or connecting to the reporting database (if we have one).
In most cases, we shouldn’t use redundant data because:
- Storing the same data more than once in the database could impact data integrity. If you store a client’s name in two different places, you should make any changes (insert/update/delete) to both places at the same time. This also complicates the code you’ll need, even for the simplest operations.
- While we could store some aggregated numbers in our operational database, we should do this only when we truly need to. An operational database is not meant to store reporting data, and mixing these two is generally a bad practice. Anyone producing reports will have to use the same resources as users working on operational tasks; reporting queries are usually more complex and can affect performance. Therefore, you should separate your operational database and your reporting database.
Now It’s Your Turn to Weigh In
I hope that reading this article has given you some new insights and will encourage you to follow data modeling best practices. They will save you some time!
Have you experienced any of the issues mentioned in this article? Do you think we missed something important? Or do you think we should remove something from our list? Please tell us in the comments below.
