

Freelancing is becoming more and more popular these days. While most freelancers are a one-man band, that’s not the only option. You could be a part of a collective and collaborate on larger and more complex projects. A data model that could power a freelancers collective’s app is the topic of today’s article.
Freelancing is not new, but it’s becoming more and more popular. Working from 9:00 to 17:00 has certain advantages, but it also comes with many disadvantages. Therefore, an increasing number of people decide to become freelancers.
Freelancers work mostly in creative industries (e.g. writers, graphic designers, translators, interpreters), in the IT industry, or on IT-related jobs. In this article, we’ll focus on IT-related projects, but the model could be used for other complex projects where collaboration is essential.
In many cases, IT projects require more than one person. If you want to build a team to complete the entire project, you’ll definitely need a way to collaborate with them. It would be great if you personally knew freelancers with the desired skills and if those freelancers had the time and desire to work on your project. But that usually is not the case, so we’ll need an IT solution that allows a large number of freelancers with different skills to work together on a project. And they won’t need to be located in the same place or even know each other.
The idea is that freelancers (and customers) could use a system that would allow them to collaborate on many different projects. It wouldn’t be a freelancing platform (e.g. Upwork) or a project management tool, but something in between the two.
The Data Model
The data model that could run one such application is pictured below. We’ll focus only on the most important application elements, so we won't go into features like chats, payment processing, and project management tools in this article.
The model consists of four subject areas:
FreelancersCustomers & ProjectsTeamsProject phases
We’ll describe each of these subject areas in the order they are listed.
Section 1: Freelancers
The first and most important subject area is Freelancers. This is where we’ll store information for all the freelancers registered in our application, including their skills.
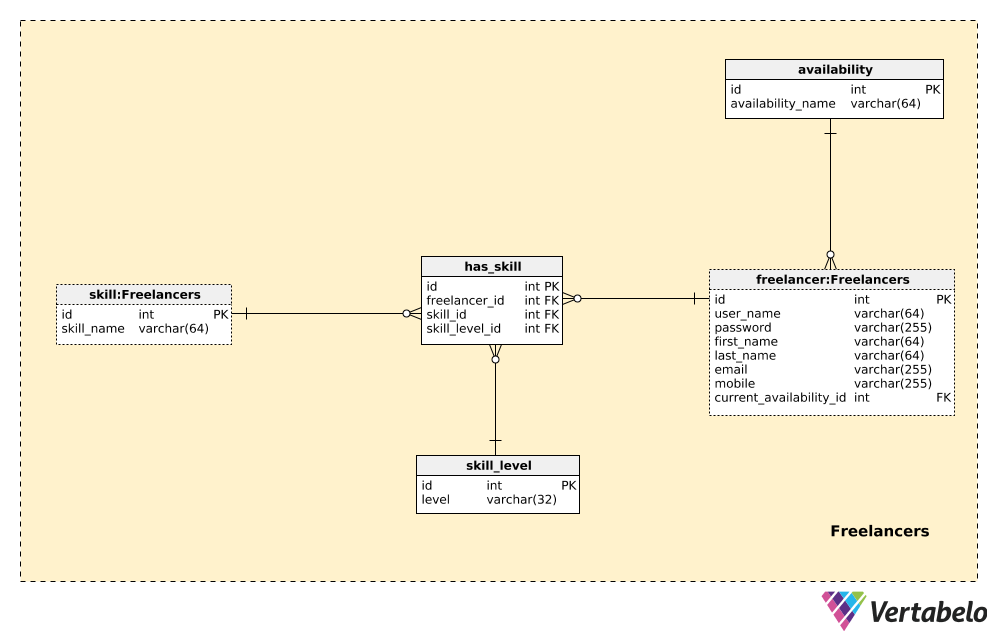
The central table here is the freelancer table and it contains a list of all freelancers who are members of our collective. They can log into our application (via web, mobile, or both) and collaborate on different projects. For each freelancer, we’ll store:
user_name– A UNIQUE username used in the sign-in process.password– A password hash value.first_nameandlast_name– The freelancer’s first name and last name.emailandphone– The freelancers’ contact details.current_availability_id– References theavailabilitydictionary and denotes if the freelancer is currently available and in what way (i.e. full-time, less than 20 hours a week, etc).
A list of all possible availability types is stored in the availability dictionary. This table contains only one UNIQUE value – availability_name. This value should be set by the freelancer according to their current engagements.
The next thing we need to store in our database is a list of freelancers’ skills and their skill levels. Skills can be used in combination with freelancers’ availability to find the best fit for new projects. We’ll use three tables to handle this requirement.
The first one, skill, is a simple dictionary containing the skill_names of all possible skills we expect we’ll need on any project. This list can include technologies, but also other skills like project management, writing, or design. Next, we need to define all the skill levels we could have. We could use numbers (e.g. from 1 to 10), or words like “basic”, “advanced”, “expert”. No matter which option we choose, we’ll need a dictionary to store these values. In our model, that is the skill_level dictionary and it also contains only one UNIQUE value, level.
The last table in this subject area, the has_skill table, is the one that will relate the freelancer, skill, and skill_level tables. It contains only references to these three tables. For each UNIQUE pair of freelancer_id – skill_id, we’ll store the current skill_level_id.
Section 2: Customers and Projects
Besides freelancers, we need customers that will use our system to manage their projects. We’ll cover all of that in the Customers & Projects subject area. We have a copy of the skill table here, but we’ve already discussed it. The other four tables are new, and we’ll explain them here.
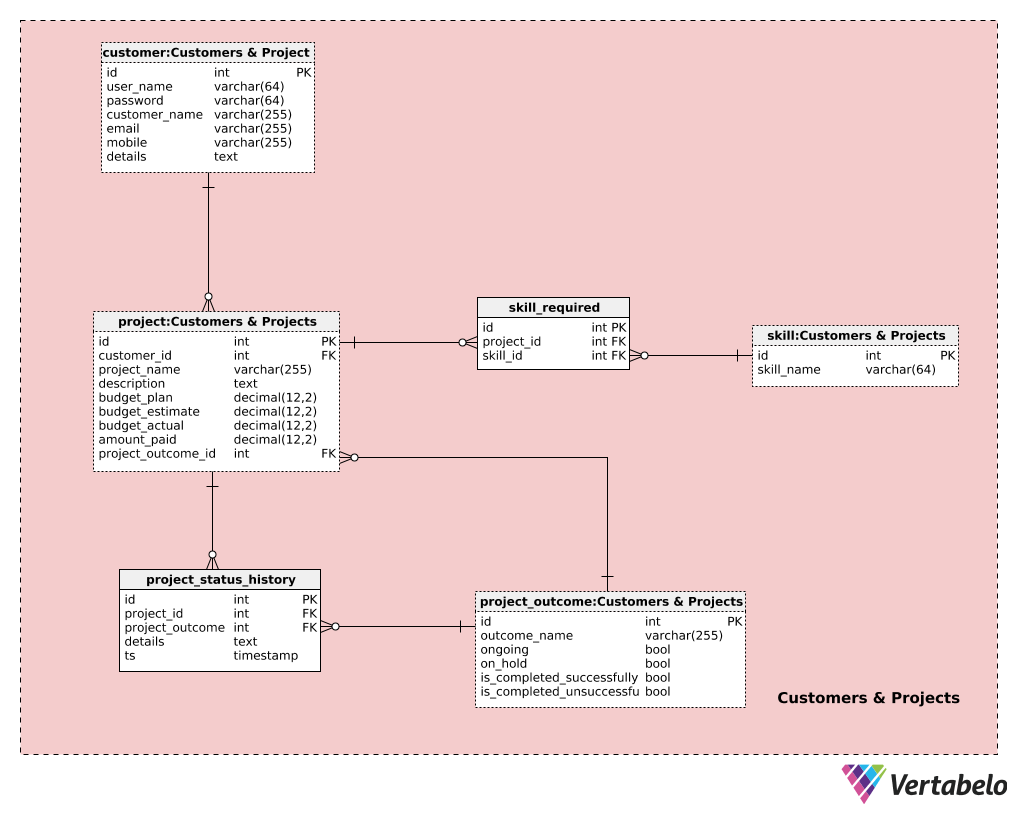
We’ll start with the customer table. Customers are also registered users of our application. They register on a different form than the one freelancers use. For each customer, we’ll store:
user_name– A UNIQUE username used during the login process.password– A password hash value.customer_name– The customer’s full name.email & mobile– The customer’s contact details.details– All additional customer details.
Customers can post their projects and include all the relevant details. All projects are stored in the project table. For each project, we’ll have a:
customer_id– A reference to thecustomerinitiating the project.project_name– The name chosen by the customer for that project.description– A full description of the project, written by the customer.budget_plan– The planned budget for the project. This value, together with the previous two values, will be inserted by the customer when the project is created. This should give the collective at least an idea of where the customer stands financially.budget_estimate– The collective’s estimated price for this project. This value is inserted after the project has been viewed. It should give the customer a feeling of how much the project will actually cost and the difference between their planned budget and the collective’s estimate.budget_actual– The actual budget for this project. This amount shall be defined along the way, according to the agreement between the customer and the collective. This could be defined at the start (i.e. a fixed-price project), but changes could be made as project requirements change.amount_paid– The actual amount paid for this project. This will be updated throughout the project, and after the project is completed successfully it should match thebudget_estimateamount.project_outcome_id– A reference to the current status of this project. After the project is initialized, this status will be that it’s a new project. All changes in status after that point will be based on actions taken by customers or by freelancers.
Besides the project description, the customer should also insert a list of all the skills required for this project. This list could be later edited by the collective or the customer (e.g. when the customer wasn’t initially sure about all skills needed). In the skill_required table, we’ll store a list of UNIQUE project_id – skill_id pairs.
To track historical changes during the project, we’ll have two more tables. One is a catalog of all possible project outcomes, and the other contains historical data.
The list of all possible outcomes is stored in the project_outcome dictionary. Outcomes could vary from the negotiation phase all the way to project close. We could have outcomes like “negotiation phase”, “project started”, “project paused by client”, “project paused by collective” , “in progress”, “delivered”, “failed” etc. For each outcome, we’ll define a UNIQUE outcome_name and set one of four values -- ongoing, on_hold, is_completed_successfully, is_completed_unsuccessfully -- to True.
The final table in this subject area contains the history of the project. For each record in the project_status_history table, we’ll store:
project_id– References the related project.project_outcome_id– References the related project outcome.details– All project details, inserted in a textual format.ts– The timestamp when this outcome was inserted.
Records in this table are inserted either automatically, after a certain phase is completed, or manually.
Section 3: Teams
So far, we have freelancers and their skills and we have projects inserted by clients. Now let’s discuss how the collective forms a team and assigns it to a project. In this subject area, we’ll look at the structure needed to achieve that. We already met the freelancer and project tables in previous subject areas, so we won’t discuss them here.
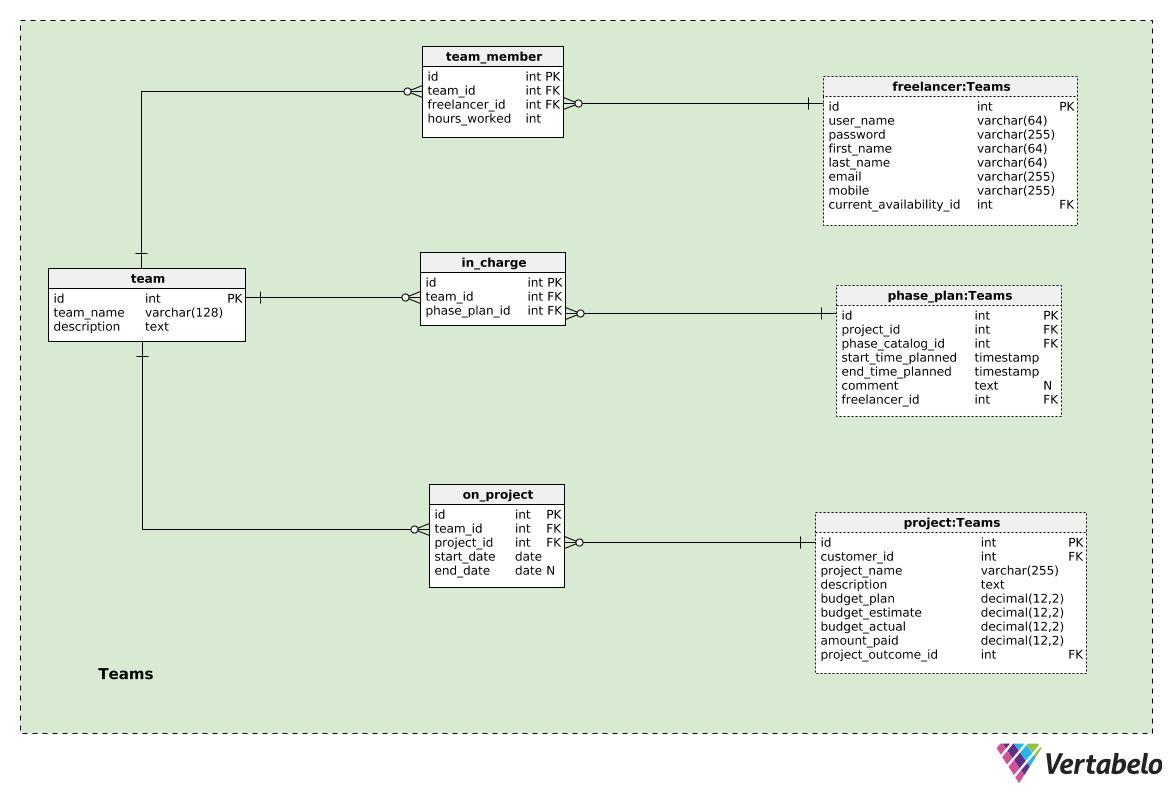
Forming a team is the main advantage of joining forces in a collective. I’ll go with the assumption that we’ll form a new team for each project, but I’ll also leave it open to the possibility that the same team could work on multiple projects. The team itself is stored in the team table. For each team, we’ll store the team_name as well as its description.
Each team is composed of team members, and they are stored in the team_member table. For each UNIQUE combination of team_id – freelancer_id, we’ll store a value denoting the number of hours_worked on that project.
Teams are assigned to projects. That relationship is stored in the on_project table. We’ll again have references to the team table (team_id) and the project table (project_id). Besides that, we’ll define the start_date and the end_date of the time when that team was working on that project. The team_id – project_id pair is NOT UNIQUE, and that allows us to assign the same team to the same project more than once, although, of course, in different time periods. We should programmatically check that there is no overlapping when the same pairs are used.
We’ll talk about phases in the next section, but it’s enough to know at this point that the phase_plan table is used to store the list of planned phases.
Now we can relate teams and planned phases by storing the UNIQUE pair team_id – phase_plan_id in the in_charge table. Please notice that more than one team could be in charge of some phase and this could be the desired behavior.
Section 4: Project Phases
In the last subject area, we’ll talk more about project execution. We have discussed four of the tables in this section before: freelancer, customer, project, and project_outcome. The remaining tables are new.

We’ll start with the phase_catalog table. This is where we’ll list all possible phases we could have during any project. We can’t know all the possible phases upfront (though we can assume most of them). If we need a new one, we’ll simply add a new value in this table. Each record is also UNIQUELY defined by the phase_catalog_name and could have the project_outcome_id defined. Some possible project phases are “new project inserted by client”, “project revised”, “proposal sent to client”, “client responded” (all these belong to the “negotiation phase” outcome); “data model developed”, “back-end development - in progress”, “front-end development – in progress” (all part of the “in progress” outcome), etc.
If a project outcome is defined, insertions and changes related to that phase will also trigger changes in the project_status_history table and a change of the project.project_outcome_id attribute value. For example, if the project previously had an outcome status set to “project paused by client”, starting a certain phase could change the current project outcome to “in progress”.
The remaining two tables are related to project phases. We’ll separately store our plan as well as how phases were actually executed.
The plan is stored in the phase_plan table, which we’ve already mentioned in a previous subject area. We’ll store our original plan of how the project should be divided into phases and how each phase should be executed. For each record in this table, we’ll store:
project_id– The ID of the related project.phase_catalog_id– The ID of the related phase name.start_time_plannedandend_time_planned– The start and end times planned for that phase.comment– An optional comment, inserted at the time we insert this record. This is a good place to define the details of what we want to achieve during this phase.freelancer_id– References the freelancer who inserted this record.
The last table in this subject area and in our model is the phase_history table. It has almost the same structure as the phase_plan table. There are two important differences:
- We have the
freelancer_idandcustomer_idattributes here. Only one of them can be set at a time, and that will denote who inserted this record. This is most likely to be a team member, but the customer may do it. - The
start_timeandend_timeattributes denote the actual start time of that phase and the actual end time. Whilestart_timewill be set when we insert a record, theend_timeattribute will be set later. - The comment attribute can be used to insert the outcome of this phase.
end_time) will trigger an insert or update of the project outcome if that phase has a related outcome in the phase_catalog. Please note that we could have two phases running at the same time, e.g. the development of a web application and a mobile application could both start after we completed work on the database. Therefore, some intervals during the planning and execution phases could overlap.
Let’s Talk About the Freelancers’ Collective Data Model
Today we have discussed a data model that could be used by a freelancers’ collective to collaborate together on complex projects. Have you ever been a part of such a collective? Would you add something to the model? Or remove something from it? Please tell us in the comments below.
