

Do you want to learn how to design a database system and map a business process to a data model? Then this post is for you.
In this article, you’ll see how to design a simple database schema for a recruitment company. After reading this tutorial, you will be able to understand how database schemas are designed for real-world applications.
The Recruitment System Business Process
Before designing any database or data model, it is imperative to understand the basic business process for that system. The database schema we’ll create is for an imaginary recruitment company or team. Let’s first see the steps involved in hiring new employees:
- Companies contact recruitment agencies to hire on their behalf. In some cases, companies recruit employees directly.
- The person responsible for recruitment starts the recruiting process. This process can have multiple steps, such as the initial screening, a written test, the first interview, the follow-up interview, the actual hiring decision, etc.
- Once the recruiters have agreed on a particular process – and this can change depending on the client, the company, or the job in question – the vacancy is advertised on various platforms.
- Applicants start applying for the job.
- The applicants are shortlisted and invited to a test or initial interview.
- The applicants appear for the test/interview.
- The tests are graded by the recruiters. In some cases, tests are forwarded to specialists for grading.
- Applicants’ interviews are scored by one or more recruiters.
- Applicants are evaluated on the basis of tests and interviews.
- The hiring decision is made.
A Recruitment System Database Schema
In view of the aforementioned process, our database schema is divided into five subject areas:
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
We’ll review each of these areas in detail, in the order they are listed. Below, you can see the entire data model.
Process
The process category contains information related to the recruiting processes. It contains three tables: process, step, and process_step. We’ll look at each one.
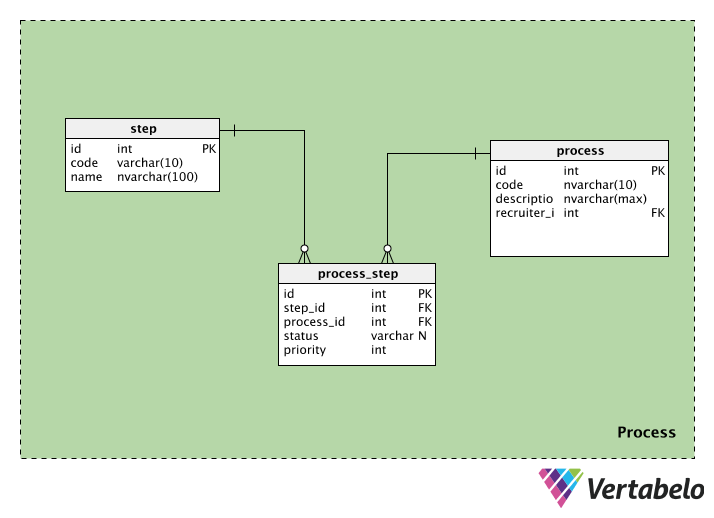
The process table stores information about each recruitment process. Every process will have a special id, a code, and a description of that process. We’ll also have the recruiter_id of the person who initiates the process.
The step table contains information about the steps followed throughout that recruitment process. Every step has an id and a code name. The name column can have values like “initial screening”, “written test”, “HR interview”, etc.
Since one process can have multiple steps and one step can be part of many processes, we need a lookup table. The process_step table contains information about each step (in step_id) and the process it belongs to (in process_id). We also have a status, which tells us the status of that step in that process; this can be NULL if the step hasn’t been started yet. Finally, we have a priority, which tells us which order to execute the steps in. The steps with the highest priority value will be executed first.
Jobs
Next we have the Jobs subject area, which stores all the information related to the job(s) we’re recruiting for. The schema for this category looks like this:

Let’s explain each of the tables in detail.
The job_category table broadly describes the type of job. We could expect to see job categories like “IT”, “management”, “finance”, “education”, etc.
The job_position table contains the actual job title. Since one title can be advertised for multiple jobs (e.g. “IT Manager”, “Sales Manager”), we’ve created a separate table for job positions. We could expect to see values like “IT Team Lead”, “Vice President”, and “Manager” in this table.
The job_platform table refers to the medium used to advertise the job opening. For instance, a job could be posted on Facebook, an online job board, or in a local newspaper. A link to that job posting can be added in the description field.
The organization table stores information about all the company who have ever used this database as part of their hiring process. Obviously, this table is important when recruiting is being done for another company.
The last table in this subject area, job, contains the actual job description. Most of the attributes are self-explanatory. We should note that this table has many foreign keys, which means that it can be used to look up the category, position, platform, the hiring organization, and the recruitment process related to that job opening.
Application, Applicant, and Documents
The third part of the schema consists of the tables that store information about job applicants, their applications, and any documents that come with the applications.
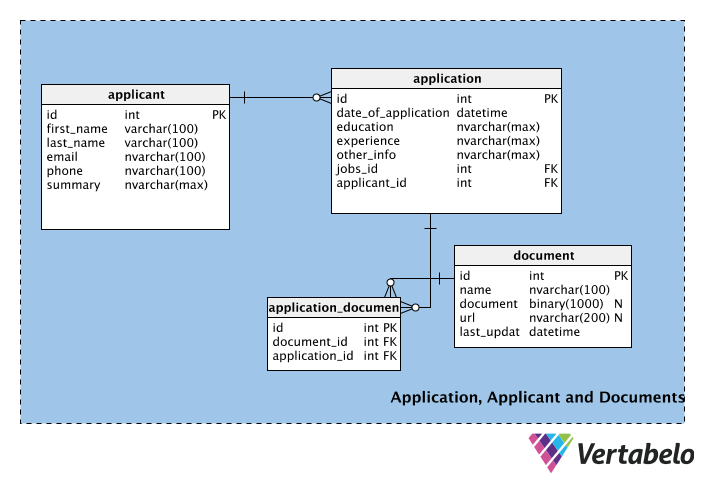
The first table, applicant, stores applicants’ personal information, such as their first name, last name, email, phone number, etc. The summary field can be used to store short profile of the applicant (i.e. a paragraph).
The next table contains information for each application, including its date. The table also contains the experience and education columns. These columns could be part of the applicant table, but an applicant may or may not want to display a particular educational qualification or job experience on every application they submit. Therefore, these columns are part of the application table. The other_info column stores any other application-related information. In the application table, the jobs_id and applicant_id are foreign keys from the job and applicant tables, respectively.
Since there can be multiple applications for each job but each application is only for one job, there will be a one-to-many relationship between the jobs and applications tables. Similarly, one applicant can submit multiple applications (i.e. for different jobs), but each application is from only one participant; we’ve implemented another one-to-many relationship between the applicants and applications tables to handle this.
The document table manages the supporting documents that applicants may attach to their application. These can be CVs, resumes, letters of reference, cover letters, etc. Note that this table has a binary column named document, which will store the file in binary format. A link to the document may be stored in the url field; the name column stores the name of document, and last_update signifies the most recent version uploaded by the applicant. Note that both document and url are nullable; neither is mandatory, and an applicant may choose to use either or both methods to add information to their application.
Not every application will have a document attached. One document can be attached to multiple applications, and one application can have multiple supporting documents. This means there is a many-to-many relationship between the application and document tables. To manage this relationship, the lookup table application_document has been created.
Tests and Interviews
Now we’ll move on to the tables that store information about the tests and interviews related to the recruitment process.
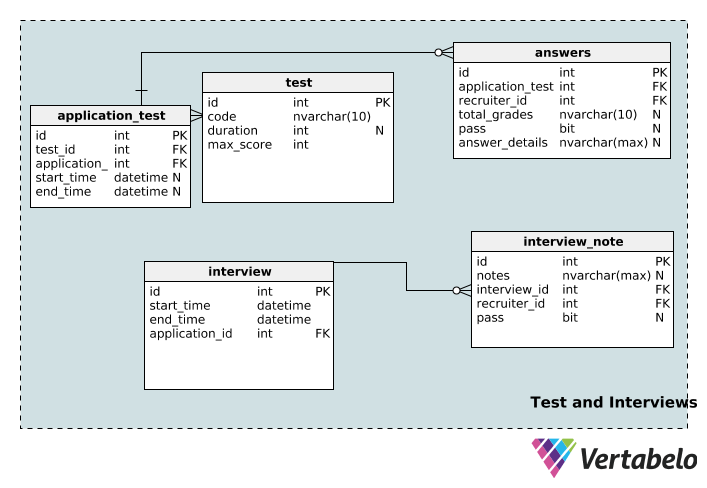
The test table stores test details including its unique id, code name, its duration in minutes, and the maximum score possible for that test.
One application can be associated with multiple tests and one test can be associated with multiple applications. Once again, we have a lookup table to implement this relation: application_test. The start_time and end_time columns are nullable, since a test might not have any specific duration, start time, or end time.
A test can be graded by multiple recruiters and one recruiter can grade multiple tests. The answers table is the table that makes this possible. The total_grades column records how well the candidate did on the test, and the pass column simply denotes if that person passed or failed. Specifics of each individual test are recorded in the answer_details column. Note that these three columns are nullable; an application test might be assigned to a recruiter who has not yet graded it. Furthermore, a recruiter can be assigned a test before it’s actually taken.
The interview table stores basic information (the start_time, end_time, a unique id, and the relevant application_id) for each interview. One interview can be associated with only one application. On the other hand, one application can have multiple interviews. Therefore, a one-to-many relationship exists between the application and interview table.
One interview can be conducted by multiple reviewers, and one reviewer can take multiple interviews. It’s another many-to-many relationship, so we’ve created the lookup table interview_note. It stores information about the interview (in interview_id), the recruiter (in recruiter_id), and the recruiter’s notes about the interview. Recruiters can also record whether or not the applicant passed the interview in the pass column, which is nullable.
Recruiters Application Evaluation and Status
The last part of our recruitment model stores information about recruiters, application statuses, and application evaluations.
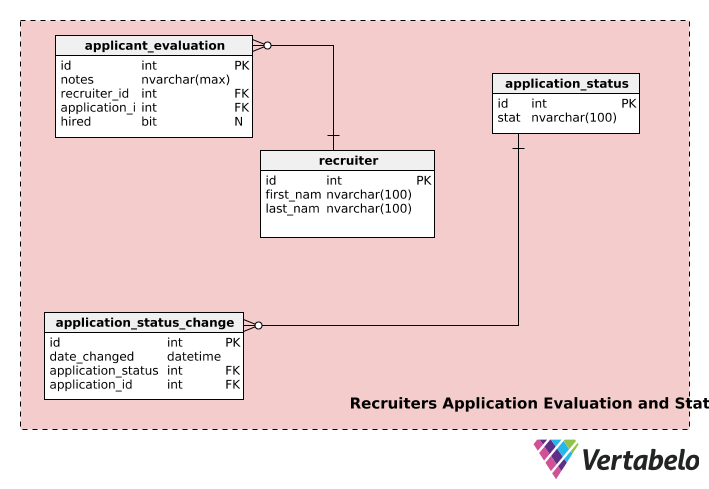
The recruiters table stores each recruiter’s first_name, last_name, and unique id number.
The application_evaluation table holds information about application evaluations. In addition to the application_id and recruiter_id, it contains recruiter’s feedback (in notes) and the final hiring decision, if any, in hired. One application can be evaluated by multiple recruiters and one recruiter can evaluate multiple applications, so both the recruiter and the application table have a one-to-many relationship with the application_evaluation table.
An application can go through multiple stages during the hiring process, e.g. “not submitted”, “under review”, “waiting for decision”, “decision made”, etc. An application will have status of “not_submitted” when user has started an application but has not submitted it for the recruiters to review. Once the application is submitted, the status is changed to “under review”, and so on. The application_status table is used to store such information.
The application_status_change table is used to maintain a record of status changes for all submitted applications. The date_changed column stores the date of the status change. This table can be handy if you want to analyze the processing time for each stage of different applications. Furthermore, the status of any particular column can be retrieved using the application_id column from the application_status_change table.
A Simple Recruiting Use Case
Let’s see how our database could help the recruiting process.
Suppose a company has assigned you to hire an IT Manager with programming experience. Our database can help us hire such a person by executing the following steps:
- The first step is to start a new hiring process. To do so, data is entered into the
processandstepstables. A recruiter can add as many steps as they need. - During the above task, the recruiter might create a new job and enter the details in the
job,job_category,job_position, andorganizationtables. Finally, a job advertisement will be placed in one of the platforms stored in thejob_platformtable. - Next, applicants will create a profile by submitting their data to the
applicanttable. Then they’ll launch a new application by entering more data into theapplicationtable. - Applicants may also attach documents to their applications. This data will be stored in the
documentandapplication_documenttables. - If a user wants to apply to more than one job, they will repeat steps 3 and 4.
- Once the application is submitted, the status of the application will be set to “submitted” (or another status name chosen by the recruiter).
- The recruiter will evaluate the application and enter their feedback in the
application_evaluationtable. At this stage, the hired column will contain no information. - Once an adequate number of applications are received, the recruiter will execute the next step shown in the
process_steptable. - If the next step is to administer some kind of test, the recruiter will create a test by adding data into the
testtable. - The test(s) created in step 9 will be assigned to a particular application. The information that assigns each test to each application will be stored in the
application_testtable. Note that, during each stage, the status of the application will keep changing. This will be recorded in theapplication_status_changetable. - Once the applicant completes the test, the grades for each application test will be marked by the recruiter and entered into the
answertable. - Once the test is taken, the next step from the
process_steptable will be executed. Let’s say the next step is the interview. - The interview data will be entered in the
interviewtable. The recruiter will enter their comments and say whether the person passed the interview or not. This will be stored in theinterview_notetable. - If the
processtable contains further interview and test steps, they will be executed until the last step is reached. - The last step in the
process_steptable is normally the hiring decision. If the applicant passes their tests and interviews and the company decides to hire them, data is entered in the hire column of theapplication_evaluationtable and the person is hired.
What Do You Think About Our Recruitment System Data Model?
In this article, we saw how to create a very simple database schema for a recruitment system. We divided the schema into four categories and then explained each of them in detail. Finally, we ran a use case to show that our schema can actually help recruit an employee.
Database design jobs are booming. Want to add to your database skills? Whether you’re a newcomer looking to learn SQL basics or a seasoned professional wanting to branch out into database design, check out LearnSQL.com’s self-paced courses.
