

What kind of data model can handle all the planning and activities used in process management? In this article, we discuss one design for a process management database.
Process management is a fairly straightforward and common concept. At its core, process management is simply deciding what needs to be accomplished – building a car or creating an app, for example – and then figuring out how to do it. Of course, the actual process itself is more complicated! It may require special tools, charts, or software, and it will certainly require a lot of planning and organization.
In this article, I’ll explain the basic ideas and terms used in process management. Then we’ll create a data model that can run a general process management app.
A Short Introduction to Process Management
Process management can be used in almost any organization or industry. Within a company, we can further separate process management into two types:
- Non-recurring activities. These usually produce something new, like a product, service or process. Non-recurring activities’ organization and realization is similar to project management.
- Recurring activities. These are usually part of the company’s core business processes. Depending on the context, they can be linked to business or manufacturing/development.
Before we start with the actual model, I would first like to answer some common questions about process management.
-
What is a process?
A process is a group of related activities that will produce a result. When I think of a process, I think of an automobile assembly line. (In my mind, it’s building a Ford Model T.) If we imagine that the assembly process takes place inside a black box, we would see materials entering the box at one end and a new Model T coming out of the other end. Everything that happens inside the black box is the process that transforms the raw materials into the Model T.
-
What are phases and activities?
Each process consists of many phases or activities (they are interchangeable, but I’ll use phase in this article). The result of each phase should be that the product (or service, or process) is one step closer to being finished. To return to our Model T illustration, putting the wheels on the car would be one phase; painting the car’s body black would be another. If something goes wrong during a phase, production will either return to a previous phase or be cancelled.
-
How are phases related?
Phases are generally completed in some kind of order, either sequentially or cyclically. They relate to one another by their place in the order.
When you think of an assembly line, it’s obvious that its phases are in a specific order. At any point in the line, we always know the previous phase and the next phase. However, a negative outcome in any phase is always a possibility, so we need the option to return to a previous phase.
We could also have phase cycles. Consider developing an IT application. After the testing phase, the app may return to the development phase because it’s not giving the desired result. This cycle repeats until the app is working properly.
We can expect that in each process we’ll have one final phase that, if completed successfully, implies that the entire process is complete.
-
What is process management?
Process management is a set of activities used to plan, execute and monitor processes. We can expect that a company will use a different process for each type of product or service it offers. For example, supplying and installing hardware requires a different process than installing an application and training its users.
At any time, we should be able to get an overview of current processes and produce reports on them. This is an extremely important feature of our model.
The Process Management Data Model
The data model consists of five main subject areas:
Users and rolesPhasesProcessesItemsActual statuses
You’ll notice that four tables are outside of any subject area. These are: role, has_role, time_required and resource_required. All of them are just copies; the originals are inside subject areas. The copies are here to simplify the model and to avoid relations overlapping.
We’ll take a closer look at each subject area in the order they are listed.
Section 1: Users and Roles

The Users and roles subject area is a general setup that can work with a lot of different data models, so we won’t spend a lot of time here.
This subject area consists of three tables:
user_account– Stores a list of all the app’s users.role– Contains a list of all the roles we could assign to users. Therole_nameattribute is UNIQUE to the table.has_role– Stores information about which users have which roles. Before we add a new role, we’ll need to check for overlapping. Otherwise, we may assign the same role twice.
More information about managing users, roles, and statuses can be found in this article.
Section 2: Phases
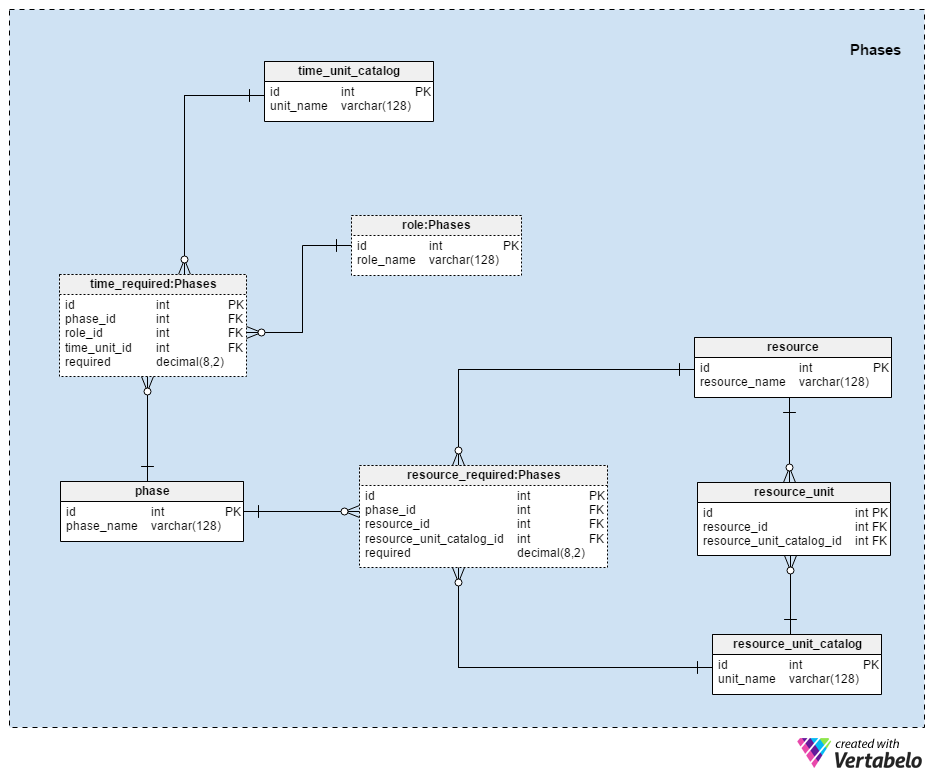
In this subject area, we’ll define all phases and the expected values for their requirements, like resources (e.g. materials, machines) and working hours. This includes any phase that is part of any process in our company. Please note that the role:Phases table is just a copy of the original role table.
The central table in this subject area is the phase table. It contains only the phase_name attribute, which can hold only UNIQUE values. If we have several different processes in our company, there is a chance that two phases could have the same name (e.g. “testing”). In order to distinguish them, we’ll define unique names for each different phase (e.g. “Testing – call center – process 1”).
For each phase, we must define how much time is needed for each role involved. The time_unit_catalog dictionary is used to define time units. We can assume that we’ll usually measure time in hours, but other units like days or minutes could be needed.
We’ll have one record in the time_required table for each role involved in a phase. Foreign keys are used to define the relevant phases, roles, and time units. This table’s required attribute stores the exact amount of time measured in the defined unit.
Besides time, we need to define all planned input materials and machine usage needed during the phase’s execution.
First, we’ll define all possible resources in the resource dictionary table. These can be for any part of any phase used in any process. Once more, the only attribute in the table is the resource_name attribute, which can contain only UNIQUE values.
Since we’re planning this app and its underlying database to handle any kind of process, we need to build in plenty of flexibility. We can’t know what units will be used to measure resources, so we’ll have a table where the user can add units as needed. These values are stored in the resource_unit_catalog. Once more, the unit_name attribute can contain only UNIQUE values.
The resource_unit table relates each resource with the units used to measure it. The foreign key pair of resource_id and resource_unit_catalog_id is the UNIQUE key of the table.
These three tables will be populated during the app’s initial system setup. Obviously, users will need to define all the resources and units used in their processes before they can use the application.
The last table in this subject area is the resource_required table. It relates resources and phases in the same manner that time_required relates phases and roles. The phase_id –resource_id pair forms the UNIQUE key of the table. The resource_unit_catalog_id attribute denotes which unit is used to measure that resource, while required contains the exact number needed for the phase. We could use only resource_unit_id here, as it has a record related with that resource_id in the resource_unit table. I’ve chosen not to do that in order to allow changes in the resource_unit table, no matter have we used unit in some previous phase or not.
Section 3: Processes
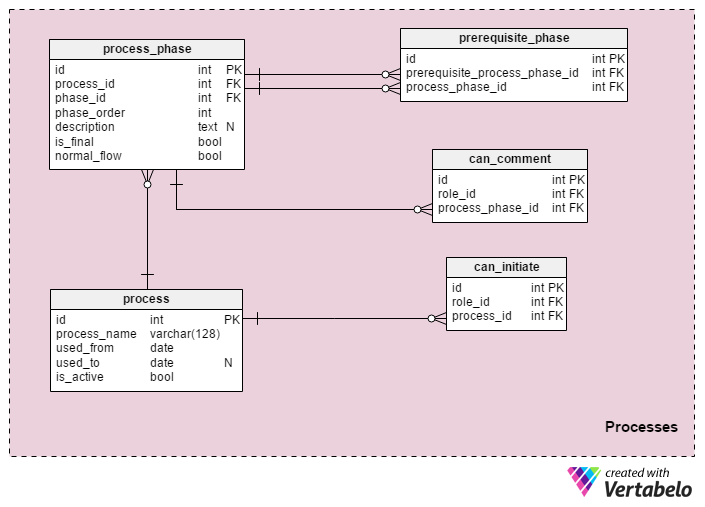
In the previous section, we defined all possible phases. In this section, we’ll do the same for every process. For each process, we’ll delineate its details and its related phases. We’ll also indicate which users can make changes to the process and which can comment on process or phase tasks.
Let’s quickly talk about how we can expect processes to exist and function. Technically, regular business processes are constant; we’ll usually keep a process as-is until the company infrastructure or organization changes. At some point, we’ll likely have one or more processes relating to the complexity of our organization. Usually, each department uses one process, but that is not always the case.
However, some processes themselves may evolve or discontinue over time. Even if we are just making changes to the process, we’ll discard the old one and create a new one in its place. This allows us to keep a history of the previous tasks that used that process.
A list of all processes used in an organization is stored in the process table. The process_name attribute contains UNIQUE values. For each process, we have to define the time we started using it (the used_from attribute). If the process is currently in use, the is_active attribute is set to True. If we are no longer using the process, then is_active is set to False and the used_to attribute must be defined.
Each process has one or more phases. We need to know the order of each phase in the process as well as the phases that preceded it. All phase-related data is stored in the process_phase table. The attributes in this table are:
process_id– The ID of the relevant process.phase_id– The ID of the related phase.phase_order– Where the phase occurs in the process order. This place will usually be unique but sometimes a process branches, leading to two phases that have the same order.description– A description of that phase’s role in the process, if needed.is_final– Denotes if this is the final phase in a process. The final phase could be the one that tells us that process completed successfully; on the other hand, the final phase might be the one where a problem arose and the process was abandoned or reworked. We’ll use the next attribute to determine if the process succeeded.normal_flow– Indicates if this phase is part of the “normal” process flow. Normal flow in this context is the expected phase order. If the process is not in normal flow, that could mean that this task should be specially monitored. If the phase’sis_finalattribute is set to True, thennormal_flowwill show if the process finished successfully.
The prerequisite_phase table is used to define all the phases that need to be completed before we can start a new phase. It might seem that the phase_order attribute could be used here, but this is not 100% accurate. Maybe we want to define the transition from a higher-order phase to a lower-order phase. For instance, if we detected errors during the testing phase, we could return to a previous phase to fix them. Aside from an ID attribute, this table contains only two foreign keys that denote the phase and its prerequisite. These two attributes together form the UNIQUE key of the table.
The last two tables in this section are the can_initiate and the can_comment tables. They provide us with the ability to define which roles can start new tasks in a process and which roles can insert comments on current tasks. In both tables, the foreign key pairs hold only UNIQUE values.
Section 4: Items
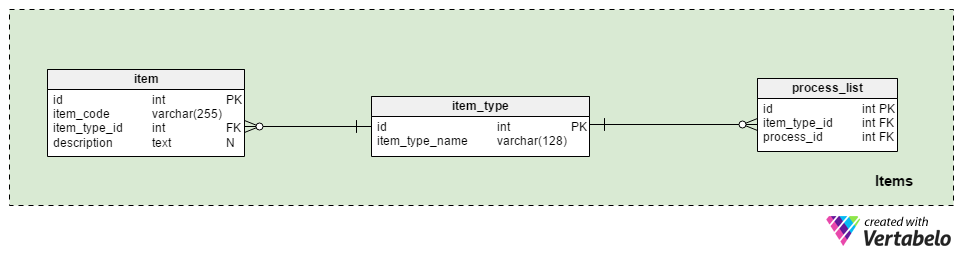
The Items area is where we’ll define all items created in a process.
Let’s start with the item_type table. This list contains all possible types of tasks, projects, or products. Output items are basically whatever the company produces and offers to clients. The item_type_name attribute is the only attribute in the table and contains only UNIQUE values.
Usually there is only one process per item type, but on occasion users may be able to choose from a few different processes. A list of all possible processes related with an item type is stored in the process_list table. The item_type_id and process_id foreign key combination is UNIQUE and the alternate key of the table.
In the item table, we’ll store an actual list of all the tasks, projects, and products we’re working on. Some examples are: actual software we’re developing as an IT company; advising one client as a consulting company; building a single car of a specific type as an automobile assembly line. Each item is uniquely defined by its item_code. We’ll also define the item’s related item_type_id, and we can add a description if we want to.
Section 5: Actual Statuses

The last subject area, Actual statuses, contains the core tables of this model. These tables relate data from the previously-mentioned subject areas.
The item_process table holds data about the process selected for an item. For each record in this table we’ll store:
item_idandprocess_id– The IDs of the selected item and process.process_started– The actual time work started on an item.process_ended– The actual time when work finished. This field can be NULL because we’ll update this attribute when we enter information about the process’ final phase.completed_successfully– Flags if the item completed successfully. It will be updated at the same time the final phase record is inserted. This is redundant data, but if we store it here we can avoid complex queries later.is_last_process– Indicates if the current process is the final process used for this item. We could have started work with one process and then decided to switch to another process. If more than one process has been used to develop an item, only one process can have this attribute set to True.has_role_id– The ID and role of a user at the time a process was initiated.
We’ll use the item_phase table to define each phase used during an item’s process. Besides the foreign keys that define the process and phase, we’ll also store the time when the phase_started and the has_role_id of the user who created the record for that phase. When the phase is finished, we’ll update the phase_ended attribute.
The phase_comment table lists all user-inserted comments regarding a phase for a selected item. This table stores the actual comment_time and comment_text, as well as the ID of the user who commented and the ID of the related phase.
The final two tables in our model are the time_used and the resource_used tables. For each phase of the process, we’ll store the actual time each user worked during that phase in the time_used table. Likewise, we’ll store how much of each resource was used in the resource_used table. Both of these values are stored in the used attribute. These two tables could be used to calculate actual costs during the process and to compare these values with planned values – e.g. to generate reports.
Share Your Thoughts on Process Management Apps and Databases
Today we talked about a process management data model. Like project management, process management is a very complex area and generalizing an app to meet all needs is hard. Still, certain rules apply to most processes, and those are the ones I’ve tried to cover in this article.
What would you change in this data model? What is your experience with existing process management tools? Tell us in the comments section!
