

Cameras, revolving doors, elevators, temperature sensors, alarms – all of these devices produce a large number of interconnected signals that are related to events happening around us. Now imagine you’re the person who needs to track statuses, produce real-time reports, and make predictions based on all this signal data. To do this, you’d first need to store that data. A data model that supports such signal processing is the topic of today’s article.
The simplest way to store incoming signals would be to simply store a textual representation of them in one huge list. This approach would allow us to perform inserts quickly, but updates would be problematic. Also, such a model wouldn’t be normalized, and therefore we won’t go in that direction.
We’ll create a normalized data model that could be used to store the data generated by different devices and also define how the devices are related. Such a model would efficiently store everything we need and could also be used for analysis and predictive analytics.
Data Model
The signal processing data model
The model consists of three subject areas:
ComplexesInstallations & DevicesSignals & Events
We’ll describe each of these subject areas in the order it is listed.
Complexes
While creating this data model, I went with the assumption that we’ll use it to track what is happening in larger complexes. Complexes vary in size from a single room to a shopping mall. It’s important that every complex has at least one device/sensor, but it will probably have many more.
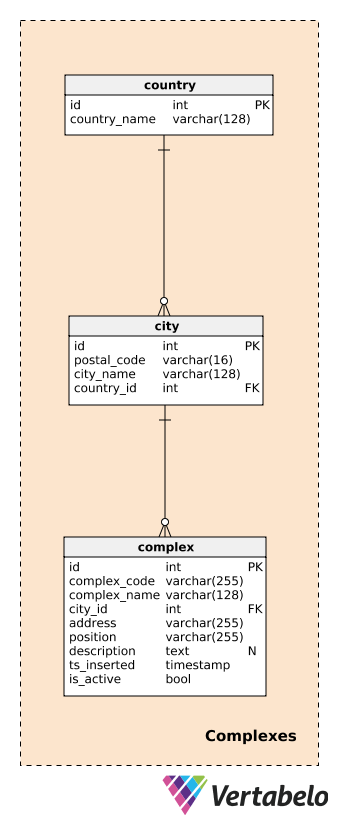
Before describing complexes, we need to define the tables handling countries and cities. These will provide a fairly detailed description of the location of each complex.
For each country, we’ll store its UNIQUE country_name; for each city, we’ll store the UNIQUE combination of postal_code, city_name, and country_id. I won’t go into detail here, and we’ll assume that each city has only one postal code. In reality, most cities will have more than one postal code; in that case, we can use the main code for each city.
A complex is the actual building or location where data-generating devices are installed. As stated before, complexes could vary from a single room or a measuring station to much larger places like parking lots, shopping malls, cinemas, etc. They are the subject of our analysis. We want to be able to track what is happening on the complex level in real time and, later, to produce reports and analyses. For each complex, we’ll define a:
complex_code– A UNIQUE identifier for each complex. While we have a separate primary key attribute (id) for this table, we can expect that we’ll inherit another identifying code for each complex from another system.complex_name– A name used to describe that complex. In the case of shopping malls and cinemas, this could be their actual and well-known name; for a measuring station, we could use a generic name.city_id– A reference to the city where the complex is located.address– The physical address of that complex.position– The complex’s position (i.e. geographic coordinates) defined in textual format.description– A textual description that more closely describes this complex.ts_inserted– A timestamp when this record was inserted.is_active– A boolean value denoting if this complex is still active or not.
Installations and Devices
Now we’re moving closer to the heart of our model. We’ll likely have a number of devices installed in each complex. We’ll also almost certainly group these devices based on their purpose – e.g. we could put cameras, door sensors, and a motor used to open and close a door in a group because they work together.
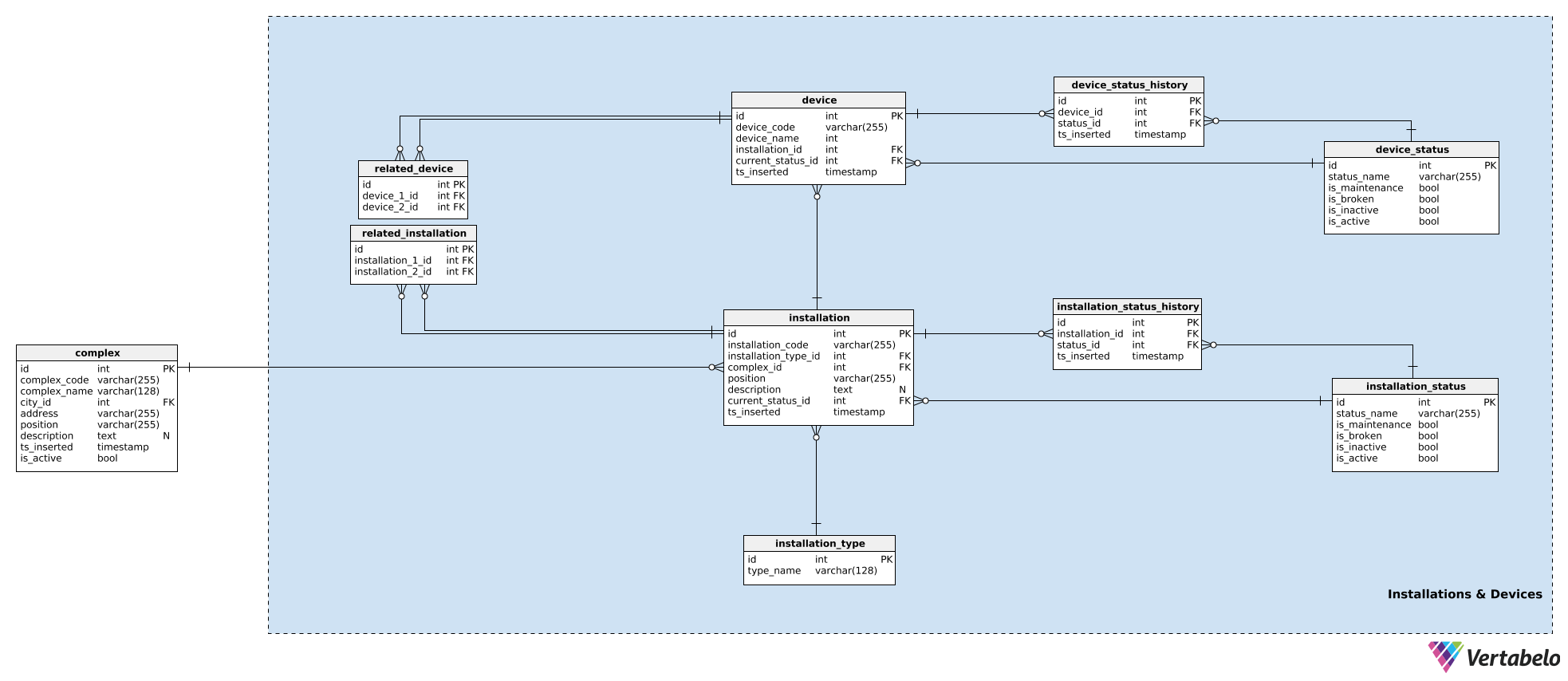
In our model, devices that work together in one complex are grouped in installations. These could be for front doors, escalators, temperature sensors, etc. For each installation, we’ll store the following details in the installation table:
installation_code– A UNIQUE code used to denote that installation.installation type_id– A reference to theinstallation_typedictionary. This dictionary stores only a UNIQUEtype_nameattribute that describes the type, e.g. escalator, elevator.complex_id– A reference to thecomplexthat installation belongs to.position– The coordinates, in textual format, of that installation inside the complex.description– A textual description of that installation.current_status_id– A reference to the current status (from theinstallation_statustable) of that installation.ts_inserted– A timestamp when this record was inserted in our system.
We’ve already mentioned installation statuses. A list of all possible statuses is stored in the installation_status dictionary. Each status is UNIQUELY defined by its status_name. Besides that, we’ll store flags denoting if that status, when used, implies that installation is_broken, is_inactive, is_maintenance, or is_active. Only one of these flags should be set at a time.
We’ve already assigned a current status to the installation. If we’re going to track what’s happening with the device, we also need to store its history. To do that, we’ll use one more table, installation_status_history. For each record here, we’ll store references to the related installation and status as well the moment (ts_inserted) when that status was assigned.
Installations are part of our complexes. While each installation is a single entity, it could still be related to other installations. (E.g. a video system at a shopping mall’s front entrance is obviously related to the mall’s front doors – people will be seen by camera first and then the doors will open.) If we want to keep track of these relationships, we’ll store them in the related_installation table. Please notice that this table contains only UNIQUE pairs of two keys, both referencing the installation table.
The same logic is used to store devices. Devices are single pieces of hardware that produce the signals we’re interested in. While installations belong to complexes, devices belong to installations. For each device, we’ll store:
device_code– A UNIQUE way to denote each device.device_name– A name for this device.installation_id– A reference to the installation this device belongs to.current_status_id– The current status of the device.ts_inserted– A timestamp when this record was inserted.
Statuses are handled in the same way. We’ll use the device_status table to store a list of all possible device statuses. This table has the same structure as installation_status and the attributes are used in the same manner. The reason for having the two separate status dictionaries is that devices and their installations could have different statuses – at least in name.
The current status is stored in the device.current_status_id attribute and the status history is stored in the device_status_history table. For each record here, we’ll store relations to the device and status as well as the moment when this record was inserted.
The last table in this subject area is the related_device table. While it’s pretty much obvious that all devices inside the same installation are closely related, I want to have the option to relate any two devices belonging to any installation. We’ll do that by storing their two device IDs in this table.
Signals and Events
Now we’re ready for the heart of the whole model.
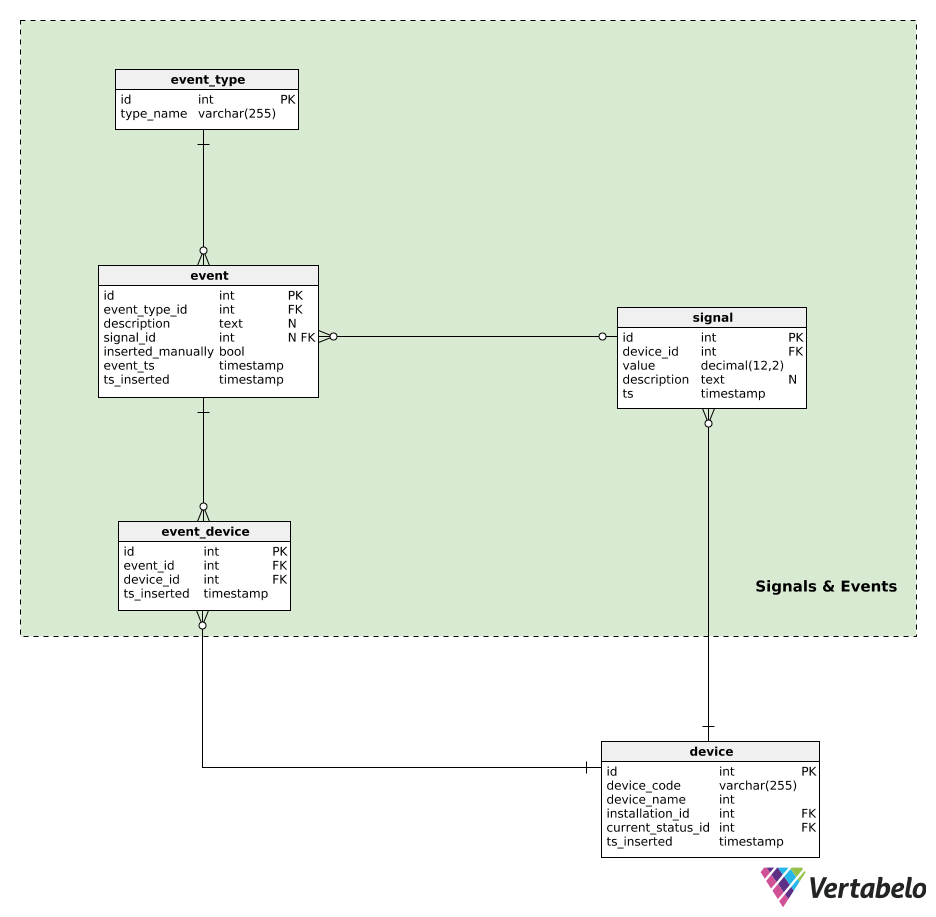
Devices generate signals. All signal data is kept in the signal table. For each signal, we’ll store the:
device_id– A reference to the device that generated that signal.value– The numerical value of that signal.description– A textual value that could contain any additional parameters (e.g. signal type, values, measurement unit used) related to that single signal. This data is stored in a JSON-like format.ts– A timestamp when this signal was inserted to the table.
We can expect that this table will get extremely heavy usage, with a large number of inserts performed per second. Therefore, database maintenance should focus on tracking the size of this table.
The last thing I want to do is to add events to our data model. Events could be automatically generated by a signal or inserted manually. One automatically-generated event could be “door open for 5 minutes”, while a manually-inserted event could be “the device had to be switched off because of this signal”. The whole idea is to store actions that occurred as a result of device behavior. Later, we could use these events while performing a device behavior analysis.
Events will be granulated by event_type. Each type is UNIQUELY defined by its type_name.
All automatically generated or manually inserted events are recorded in the event table. For each record here, we’ll store:
event_type_id– A reference to the related event type.description– A textual description of that event.signal_id– A reference to the signal, if any, that caused the event.inserted_manually– A flag denoting if this record was inserted manually or not.event_tsandts_inserted–Timestamps when this event actually happened and when a record of it was inserted. These two could differ, especially when event records are inserted manually.
The last table in our model is the event_device table. This table is used to relate events with all the devices that were involved. For each record, we’ll store the UNIQUE pair event_id – device_id and the timestamp when the record was inserted.
What Do You Think About Our Signal Processing Data Model?
Today, we’ve analyzed a simplified data model we could use to track signals from a set of devices installed in different locations. The model itself should be enough to store everything we need to track statuses and perform analytics. Still, a lot of improvements are possible. What could we add? Please tell us in the comments below.
